Informática Aplicada a la Gestión Pública. Facultad de Derecho (GAP) UMU
Capítulo 6. Bases de datos relacionales.
![]()
6.1 Estructura de las Bases de Datos Relacionales
6.2 Propiedades de las Relaciones
6.3 Claves en el Modelo Relacional
6.4 Lenguajes de Consulta a Bases de Datos Relacionales
IMPORTANTE se recomienda acceder previamente a la siguiente información:
Teoría de conjuntos (Wikipedia)
Teoría elemental de conjuntos (Invitación a las matemáticas)
Álgebra (Wikipedia)
Cálculo (Wikipedia)
6.1.- Estructura de las Bases de Datos Relacionales
Es la estructura más utilizada actualmente. Los datos están estructurados en tablas:- Cada fila es un registro o entidad.
- Cada columna es un campo de ese registro.
Esta estructura es similar al concepto matemático de relación, por ello ha tenido tanto auge, ya que todas las teorías y reglas matemáticas sobre relaciones son aplicables, lo que hace que sea fácil de formalizar.
A la tabla se le llama relación, y a cada fila tupla; a cada columna de una tupla se le llama atributo, es en esto en lo que se diferencia del modelo matemático.
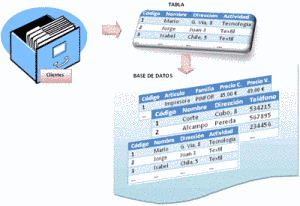
Fuente de la imagen: adrformación
Convencionalismos
- Los nombres de relaciones siempre en minúsculas.
- Cada tupla se puede representar por una variable de tupla.
- Cada atributo se representa por su nombre.
- Cardinalidad = Nº de tuplas de una relación.
- Grado = Nº de atributos de la relación.
- Cada atributo puede tomar valores dentro de su dominio de atributo (conjunto de valores posibles)
- Esquema = Definición global y general de una relación.
- El esquema de una relación se representa en letras mayúsculas: r(R) donde r sería el nombre de la relación y R el nombre del esquema.
- Formato de un esquema: Nom_esquema=(lista de atributos con sus dominios).
- Instancia de una relación = Información que contiene una relación en un momento determinado.
-
Alumnos = (dni: dom_dni; nombre: dom_nombre; edad: dom_edad).
Obsérvese que la primera letra de Alumnos es mayúscula (es un esquema).
6.2.- Propiedades de las Relaciones
Miden su grado de bondad/aproximación al modelo real matemático por una serie de "formas normales", según se sube en las formas se dice que la relación está mejor diseñada. Al menos debe estar en la primera forma normal (1NF) y para ello debe cumplir:- No hay duplicación de tuplas.
- No hay orden entre las tuplas.
- No hay orden entre los atributos (se accede a través de su nombre).
- No existen atributos que no sean atómicos (una casilla un dato). Es decir, no existe la posibilidad de tener una tabla como la siguiente:
| Alumno | Asignatura |
| José | Cálculo |
| Algebra | |
| Física |
- no es correcta, sin embargo si lo es esta otra:
| Alumno | Asignatura |
| José | Cálculo |
| José | Algebra |
| José | Física |
Ejemplo:
- Alumno = (nombre: dom_nombre; nº: entero)
Asignatura = (nº: entero; asignatura:dom_asignatura).
| Nombre | Núm. |
| José |
15 |
| Antonio |
17 |
| Pedro |
18 |
| Num. | Asignatura |
| 15 |
Cálculo |
| 15 |
Algebra |
| 15 |
Física |
6.3.- Claves en el Modelo Relacional
Debe existir un atributo o conjunto de atributos que identifique de un modo único a una tupla; a ese atributo se le llamaría superclave (puede ser el conjunto formado por todos los atributos), al menos hay uno siempre.Para una r(M) diremos que un subconjunto de atributos (K) del esquema será clave de la relación si para toda tupla t1 ≠ t2 se cumple que t1[k] ≠ t2[k] (es decir, dadas dos tuplas diferentes el valor de la clave también lo es).
Dentro de las superclaves, llamaremos claves candidatas a las superclaves más pequeñas (aquellas superclaves que carecen de subconjuntos propios que sean también superclaves). De entre todas las que haya, es el usuario el que decide cual es la primaria, las demás se llaman alternativas.
Reglas de Integridad:
- Integridad de Identidad: La clave primaria de una relación no puede contener valores nulos.
- Integridad de Referencia: Cuando en una relación hay un atributo que hace referencia a una clave primaria de otra relación, el atributo debe tener un valor coincidente con alguno de la clave primaria o como mucho ser nulo (es decir, no puede tener un valor que no exista entre los valores de la clave primaria en la primera relación).
6.4.- Lenguajes de Consulta a Bases de Datos Relacionales
Los podemos dividir en dos tipos: Lenguajes Formales y Lenguajes Comerciales. Los lenguajes formales están basados en el álgebra relacional o en el cálculo relacional. Solamente se han descrito para consulta a Bases de Datos (existen lenguajes comerciales que además de consulta permiten otras operaciones).El álgebra relacional tiene procedimientos (procedimental), mientras que los lenguajes basados en el cálculo relacional son aprocedimentales. Dentro del cálculo relacional se distingue entre cálculo relacional orientado a tuplas y cálculo relacional orientado a dominios.
Los lenguajes comerciales, en su mayoría usan enfoques tanto procedimentales como aprocedimentales, o lo que es lo mismo, no son lenguajes puros como los formales. De esta manera hacen su sintaxis más amigable al usuario.
4.1 Lenguajes Formales
Álgebra Relacional
-
A) Operaciones fundamentales: Tiene cinco por medio de las cuales se puede realizar cualquier consulta. Son las siguientes:
1.- Selección (σ). Es una operación unaria (actúa sobre una relación única). Sirve para obtener determinadas tuplas de una relación, basándose en que dichas tuplas cumplan un predicado determinado P. Su sintaxis es la siguiente: σP (r), donde r es la relación sobre la que se actúa y P es el predicado que debe cumplirse.
Si por ejemplo tenemos la relación: estudiante = (NE, nombre, edad, dccion) y queremos seleccionar al estudiante 2249 tendremos que hacer:
σ NE =2249(estudiante)
El predicado de selección admite los siguientes operadores relacionales: < , ≤ , > , ≥ , = . Además un predicado puede estar compuesto por varias condiciones unidas por los conectivos ∧ u ∨.
Ejemplo:
σ nombre = "Pepe" ∧ edad > 25 (estudiante)
De esta manera se seleccionarían todos los estudiantes llamados Pepe y cuya edad supere los 25 años.
2.- Proyección (Π): Es también una operación unaria. Proyecta una nueva relación con un nuevo esquema en el cual aparezcan solamente los atributos que se especifican en la operación.
Sintaxis: Π A1 ,..., An (r). Donde A1 ,...., An es la lista de atributos y "r" la relación sobre la que se actúa. Si, por ejemplo, queremos tener toda la relación de estudiantes, pero sólo con el nombre haríamos:
Πnombre (estudiante)
Si quisiésemos obtener el nombre del estudiante 2249:Πnombre (σ NE = 2249 (estudiante))
3.- Producto Cartesiano (r1 x r2): Si el número de tuplas de r1 es n1, y el número de tuplas de r2 es n2, el número de tuplas de la relación obtenida será n1·n2.
Veamos un ejemplo: Supongamos que tenemos las siguientes relaciones:
Cliente = (nombre_cliente, ciudad, calle)
Sucursal = (nombre_sucursal, activo, ciudad)
Prestamo = (num_prestamo, nombre_sucursal, nombre_cliente, importe)
Deposito = (num_cuenta, nombre_sucursal, nombre_cliente, saldo)
Si realizamos el producto cliente x prestamo, el esquema sería la unión de los esquemas:
(cliente.nombre_cliente, ciudad, calle, num_prestamo, nombre_sucursal, prestamo.nombre_cliente, importe)
Como tuplas obtenemos las posibles combinaciones de tuplas de cliente con tuplas de prestamo.
Habrá muchas tuplas de la nueva relación en las que se cumplirá que:
t[cliente.nombre_cliente] ≠ t[prestamo.nombre_cliente]
Por ello, normalmente la operación de producto cartesiano va unida a una selección que de entre todas las posibles combinaciones de tuplas selecciona las que cumplen unas condiciones. Por ejemplo, queremos localizar los clientes y las ciudades donde viven que tengan un préstamo.
Π prestamo.nombre_cliente, ciudad (σprestamo.nombre_cliente = cliente.nombre_cliente (cliente x prestamo))
4.- Unión de Conjuntos (r1 ∪ r2): Actúa sobre dos relaciones uniéndolas. El resultado es, por tanto, una nueva relación con el mismo esquema que las relaciones implicadas y con un número de tuplas que es la unión de las tuplas de r1 y r2 (los elementos duplicados se desechan).
r1 y r2 deben tener el mismo esquema, es decir, los dominios de los atributos i-ésimos de cada uno de los esquemas debe coincidir.
En el ejemplo que estamos considerando, no podríamos hacer la unión de cliente con préstamo, pero sí sería posible hacer esto otro por ejemplo
(Π nombre_cliente (cliente)) ∪ (Πnombre_cliente (prestamo))
Con la anterior operación obtendríamos los nombres de los clientes que tienen préstamo o no. En la práctica esta sería una operación inútil, puesto que se supone que todos los que tienen un préstamo en un banco son automáticamente clientes del banco. Veamos otra unión que sería de mayor utilidad: si queremos conocer los clientes que tienen en la sucursal 2 una cuenta, un préstamo, o ambas cosas, la operación a realizar sería:
(Π nombre_cliente (σnombre_sucursal = "2" (prestamo))) ∪ (Π nombre_cliente(σnombre_sucursal = "2"(deposito)))
5.- Diferencia de Conjuntos (r1 - r2): Es una operación binaria que da como resultado una relación con los elementos que están en r1, y no están en r2. Lógicamente r1 y r2 deben tener el mismo esquema.
Esta operación se podría utilizar, si por ejemplo queremos saber el nombre de los clientes que tienen un préstamo en la sucursal principal, pero que no tienen cuenta en dicha sucursal:
(Πnombre_cliente (σnombre_sucursal = "Principal" (prestamo))) - (Π nombre_cliente (σnombre_sucursal = "Principal" (deposito)))
Con las cinco operaciones definidas (operaciones fundamentales) se puede realizar cualquier consulta en álgebra relacional. Aun así, existen otras operaciones (operaciones adicionales), que facilitan algunos tipos de consulta frecuente, y que puede resultar muy tedioso el hacerlas mediante las operaciones fundamentales.
B) Operaciones Adicionales:
1.- Intersección de Conjuntos (r1 ∩ r2): Da como resultado una relación que contiene los elementos comunes a r1 y r2. Es adicional, ya que es equivalente a realizar r1 - (r1 - r2).
Por ejemplo, podríamos obtener los nombres de los clientes que tienen depósito y préstamo al mismo tiempo en la sucursal 10.
(Π nombre_cliente (σnombre_sucursal = "10" (prestamo))) ∩ (Πnombre_cliente (σnombre_sucursal ="10" (deposito)))
2.- Unión Join o Producto Theta (r1 Θ P r2): Es una forma de expresar un producto cartesiano que lleva implícita una selección. p representa el predicado de la selección. De esta manera, otra forma de conocer los nombres de los clientes que tienen préstamo, cuenta o ambas cosas en la sucursal 10 sería:
(Πnombre_cliente (σnombre_sucursal = "10" (prestamo))) Θ prestamo.nombre_cliente = deposito.nombre_cliente (Πnombre_cliente (σnombre_sucursal = "10" (deposito)))
Otra forma de conseguir esto mismo sería:Πprestamo.nombre_cliente (prestamo Θprestamo.nombre_cliente = deposito.nombre_cliente ∧deposito)
prestamo.nombre_sucursal = "10" ∧
deposito.nombre_sucursal = "10"
Podemos afirmar que:
r1 Θ P r2 = σP (r1 x r2)
3.- Producto Natural (r1ℵr2): Mejora la operación anterior, devolviendo directamente las tuplas que tienen atributos comunes. En otras palabras, realiza la proyección sobre la unión de los esquemas, es decir, elimina uno de los atributos comunes a ambas relaciones y selecciona aquellas tuplas cuyos atributos comunes coinciden en valor.
Π nombre_cliente (σnombre_sucursal = "10" (prestamoalefsym;deposito))
Dados r1(R1) y r2(R2) dos relaciones con sus respectivos esquemas, se cumple la siguiente igualdad:
r1 ℵr2 = ΠR1 ∪ R2 (σr1.A1 =r2.A1 ∪ .........∪ r1.An = r2.An (r1 x r2))
Al ser unión de esquemas, como los elementos de los esquemas son los nombres de los atributos, si existe una columna común a R1 y R2 sólo aparecerá una vez.
Cálculo Relacional
-
A. Cálculo Relacional Orientado a Tuplas
En este lenguaje, expresamos variables que representan tuplas. Si por ejemplo existe una tupla t contenida en una relación r escribiremos t ∈ r. Si queremos expresar el valor que toma el atributo A para la tupla t, lo haremos de la siguiente forma: t[A].
Como dijimos, el cálculo relacional es aprocedimental (no tiene procedimientos), por tanto cuando deseamos obtener un conjunto de tuplas (una relación) a partir de otras tenemos que expresarlo usando los medios que el cálculo relacional nos ofrece, si por ejemplo, queremos obtener una relación con el conjunto de tuplas que cumplen el predicado P, tendremos que expresarlo de esta manera: {t / P(t)}. Veamos un ejemplo práctico: "Queremos tener una lista completa de todos aquellos clientes que tienen un préstamo cuyo importe sea más de un millón" (selección).
{t / t∈ prestamo ∧ t[importe] > 1000000}
El cálculo relacional, disponemos también del cuantificador ∃, que quiere decir que existe al menos una tupla que cumpla las condiciones que se especifiquen posteriormente. Este nuevo cuantificador nos sirve para realizar proyecciones. "Queremos saber los nombres de los clientes que poseen un préstamo de más de un millón".
{t / ∈ s∈ prestamo ∧ s[importe] > 1000000 ∧ t[nombre_cliente] = s[nombre_cliente] }
Con la anterior operación definimos una nueva relación que consta de un sólo atributo (nombre_cliente).
Hasta ahora hemos usado el conectivo ∧ , pero también podremos usar ∨ y ¬ , que son el "o lógico" y el "no lógico" respectivamente. Con estos conectivos podemos realizar la unión, diferencia e intersección de conjuntos. "Queremos obtener una relación con los nombres de los clientes que o bien tienen una cuenta, o bien un préstamo, o ambas cosas en la sucursal 10" (unión).
{ t / ∃ s (s∈ prestamo ∧ t[nombre_cliente] = s[nombre_cliente] ∧ s[nombre_sucursal] = "10" ) ∪ ∃(u∈ deposito ∧ t[nombre_cliente] = u[nombre_cliente] ∧ u[nombre_sucursal] = "10") }
Como vemos el conectivo ∨ actúa aquí como unión, haciendo incluso que los clientes que tengan depósito y préstamo, aparezcan solamente una vez.
Si queremos realizar una intersección de conjuntos, por ejemplo obtener una relación de todos los clientes que tienen depósito y préstamo en la sucursal 10, bastaría cambiar el ∨ anterior por un ∧ . Por último para hacer una diferencia, habrá que cambiar el ∨ por un ∧ ¬ , con lo que obtendremos los nombres de los clientes que tienen préstamo en la 10 pero no tienen depósito en dicha sucursal.
Por último, veamos como se realizaría un producto cartesiano. Como ejemplo pondremos el siguiente: "Queremos obtener el nombre de los clientes con préstamo en la sucursal principal, y las ciudades en las que viven".
{t / ∃ s (s∈ prestamo ∧ t[nombre_cliente] = s[nombre_cliente] ∧ s[nombre_sucursal] = "Principal" ∧ ∃ u (u∈ cliente ∧ u[nombre_cliente] = s[nombre_cliente] ∧ t[ciudad] = u[ciudad] ))}
B Cálculo Relacional Orientado a Dominios:
Los datos se guardan en variables correspondientes a atributos. Las variables se refieren a atributos, lo que en cálculo relacional orientado a tuplas era t[A1] es ahora A1, por tanto si queremos hablar de una tupla tenemos que nombrar todas las variables correspondientes a los atributos de esa tupla. (< x1, x2, ....., xn >). Por ejemplo, una tupla de prestamo se expresaría de la siguiente forma: < p, s, c, i > con:
p = num_prestamo; s = nombre_sucursal; c = nombre_cliente; i = importe;
En el cálculo relacional orientado a dominios, la expresión general tendrá la forma: { < x1, x2, ....., xn > / P(< x1, x2, ....., xn >) }
Veamos como se llevarían a cabo las distintas operaciones en este lenguaje por medio de ejemplos:
-
Selección: Queremos los nombres de los clientes, número de sucursal, número de prestamo e importe de todos aquellos préstamos cuyo importe sea superior a un millón de pesetas:
{ < p, s, c, i > / < p, s, c, i > ∈ prestamo ∧ i > 1000000 }
Proyección: Utilizaremos la cláusula ∈ . Por ejemplo sólo queremos los nombres de los clientes con préstamo superior a un millón.
{ < c > / ∈ < p, s, c, i > ∈ prestamo ∧ i > 1000000 }
Unión: Nombre de clientes que tengan préstamo, depósito o ambas cosas en la sucursal principal.
{ < c > / ∃ < p, s, c, i > ∈ prestamo ∧ s = "Principal" V ∃ < s, cu, c, sa > ∈ deposito ∧ s = "Principal" }
Para la intersección y la diferencia, al igual que en al C.R. orientado a tupla basta sustituir el ∨ por un ∧ o un ∧ ¬ respectivamente.
Al igual que el álgebra relacional, el cálculo relacional tampoco es amigable para el usuario, por esta razón se han desarrollado lenguajes comerciales orientados al usuario, y que se basan en alguno de los lenguajes formales).




Escepticismo en España
Escepticismo en América
TUTORÍAS
Rafael Menéndez-Barzanallana Asensio
Departamento Informática y Sistemas. Universidad de MurciaBajo Licencia Creative Commons 3.5
Actualizado 2011/11/26
