Generalidades
El diccionario
De las numerosas definiciones de diccionario, se citan dos: la de Kenneth Whittaker, según el cual, un diccionario es aquella «obra que lista palabras de una lengua o tema o la obra que da información bajo entradas ordenadas alfabéticamente» y la de María Moliner, que apunta la idea de una obra en más de una lengua al definirlo como «libro en que está la serie de palabras de un idioma o de una materia determinada, colocadas alfabéticamente y explicadas, o bien con su equivalencia en otro idioma».Sin embargo, el diccionario no es la única obra que reúne términos con sus equivalentes en otras lenguas o con definiciones. A veces hay que buscar el significado de las palabras que nos interesan o su traducción a otra(s) lengua(s) en fuentes que no se presentan como diccionarios pero que cumplen una función compilatoria similar; son léxicos, glosarios, vocabularios, tesauros, enciclopedias, e incluso, guías, manuales, atlas, etc. Además estas obras pueden publicarse bajo otros títulos, de tal manera que pueden pasarle inadvertidas al traductor. Es lo que ocurre con Il grande libro dei proverbi, Abecedario de dichos y frases hechas, Colección de sinónimos de la lengua castellana o Nuevas palabras, (Parole nuove), etc.
Pueden ser muchas y variadas las causas que den al traste con los esfuerzos del traductor por encontrar una palabra. Sin embargo los diccionarios no son más que herramientas. Es quien traduce el que debe tomar las decisiones oportunas y el responsable final de su texto, por lo que cabe sólo apelar a su discernimiento y a su prurito profesional. Por supuesto que una sólida formación y un conocimiento en profundidad de las lenguas que maneja y de los campos en los que ejerce su profesión son siempre un buen comienzo.
En cuanto a la calidad de los diccionarios, no cabe duda de que en las librerías encontramos algunas obras excelentes junto a muchas otras mediocres o deleznables. A pesar de las indudables (y muchas veces inevitables) deficiencias que presentan las obras de consulta, un traductor debe saber cómo usar un diccionario, cuándo y para qué y es habitual que dedique muy poco tiempo a familiarizarse con las herramientas de trabajo.
Cada diccionario, por otra parte, es una obra salida de las manos de un determinado autor, que se ha planteado unos objetivos y que ha empleado ciertos criterios de selección y de disposición de las entradas. Ignorar esto significa, en el mejor de los casos, ser incapaz de sacarle jugo a una obra tan excelente; en el peor, nos arriesgamos a comprar obras inútiles y a perder tiempo en búsquedas mal planteadas.
Por último, la vorágine de información en la que vivimos inmersos y la revolución originada por las TIC han modificado notablemente la búsqueda referencial y terminológica; muchas palabras que no se encuentran en diccionarios convencionales, pasan a ser localizadas mediante los nuevos formatos en los que se presentan las obras y, por supuesto, a través de nuevas formas de consulta, por ejemplo, las redes sociales, foros y listas de distribución.
¿Qué es un diccionario de datos en sistemas de información?
El diccionario de datos es un listado organizado de todos los datos que pertenecen a un sistema. Contiene las características lógicas de los datos que se van a utilizar, incluyendo nombre, descripción, alias, contenido y organización. Estos diccionarios se desarrollan durante el análisis de flujo de datos y ayudan a los analistas informáticos que participan en la determinación de los requerimientos del sistema, evitando así malas interpretaciones o ambigüedades, su contenido también se emplea durante el diseño del proyecto.En un diccionario de datos se encuentra la lista de todos los elementos que forman parte del flujo de datos de todo el sistema. Los elementos más importantes son flujos de datos, almacenes de datos y procesos. El diccionario de datos guarda los detalles y descripción de todos estos elementos. Desde el punto de vista estadístico, este diccionario debe de tener la variable, el tipo de variable, su definición como también su delimitación espacial.
Traductores de lenguajes de programación
Un traductor es un programa que toma como entrada un texto escrito en un lenguaje, denominado fuente y da como salida otro texto en un lenguaje, llamado objeto.En 1950, John Backus John Backus (Filadelfia, 1924 - Ashland, 2007) Matemático estadounidense. Tras cursar estudios en Pottstown, Pensilvania, comenzó estudios de química en la Universidad de Virginia en 1942, que abandonó un año más tarde por falta de interés. Marchó al ejército, donde recibió instrucción médica y fue ayudante de neurocirugía en un hospital de Atlantic City. Inició luego estudios de medicina, que volvió a abandonar.
Trasladado a Nueva York, realizó un curso de radiotecnia y comenzó en la Universidad de Columbia estudios de matemáticas. Licenciado en 1949, comenzó a trabajar para la compañía IBM como programador, donde desarrolló FORTRAN, el primer lenguaje de programación de alto nivel, en 1957. Dos años más tarde desarrolló la notación normalizada que lleva su nombre (BNF, siglas de Backus Normal Form), que describe la sintaxis de los lenguajes de alto nivel. También desarrolló un lenguaje de programación funcional de aplicaciones científicas llamado FP." dirigió una investigación en IBM con la finalidad de lograr un lenguaje algebraico. En 1954 empezó a desarrollar un lenguaje que permitía escribir fórmulas matemáticas de manera traducible por un ordenador. Lo llamaron Fortran Fortran (previamente FORTRAN) (contracción del inglés Formula Translating System) es un lenguaje de programación alto nivel de propósito general, procedimental e imperativo, que está especialmente adaptado al cálculo numérico y a la computación científica. Desarrollado por IBM para el equipo IBM 704, y usado para aplicaciones científicas y de ingeniería, FORTRAN vino a dominar esta área de la programación desde el principio y ha estado en uso continuo por más de medio siglo en áreas de cómputo intensivo tales como la predicción numérica del tiempo, análisis de elementos finitos, dinámica de fluidos computacional (CFD), física computacional y química computacional. Es uno de los lenguajes más populares en el área de la computación de alto rendimiento y es el lenguaje usado para programas que evalúan el desempeño (benchmark) y el ranking de los supercomputadores más rápidos del mundo. (FORmulae TRANslator), fue el primer lenguaje considerado de alto nivel. Se introdujo en 1957 para el uso del ordenador IBM 704 y permitía una programación más cómoda y breve que lo existente hasta ese momento (lenguaje máquina), lo que suponía un considerable ahorro de trabajo.
Así surgió el concepto de un traductor, como un programa que traducía un lenguaje a otro lenguaje. En el caso particular de este lenguaje, su función era traducir un lenguaje de alto nivel a su equivalente en lenguaje de bajo nivel o de máquina mediante un proceso de compilación, por lo que por primera vez se empleó el término compilador.
Ensambladores
El término ensamblador (del inglés assembler) se refiere a un tipo de programa informático que se encarga de traducir un fichero fuente escrito en lenguaje ensamblador, a un fichero objeto que contiene código máquina, ejecutable directamente por la máquina para la que se ha generado. El propósito para el que se crearon este tipo de aplicaciones es la de facilitar la escritura de programas, ya que escribir directamente en código binario Es un sistema de representación de textos o de procesadores de instrucciones de una computadora, que hace uso del sistema binario, en tanto, el sistema binario es aquel sistema de numeración que se emplea en las matemáticas y en la informática y en el cual los números se representan usando únicamente las cifras cero y uno (0 y 1). , que es el único código entendible por el ordenador, actualmente es en la práctica imposible. La evolución de los lenguajes de programación a partir del lenguaje ensamblador originó también la evolución de este programa ensamblador hacia lo que se conoce como programa compilador.Preprocesadores
Traduce un lenguaje de alto nivel a otro, cuando el primero no puede pasar a lenguaje máquina directamente.Intérpretes
Traducen lenguaje de alto nivel a lenguaje máquina, se encargan de traducir cada instrucción, una por una (o cada línea de instrucciones) contenida en un programa escrito en cualquier lenguaje de alto nivel a instrucciones en código binario, comprensible por los ordenadores. La ejecución se da de inmediato.Los intérpretes no producen código objeto, por ello la ejecución de un programa requiere forzosamente del código fuente. Además, los programas en lenguaje interpretado se ejecutan con más lentitud que aquellos en lenguaje compilado.

Compiladores
Es el tipo de traductor más conocido. Se trata de un programa que traduce código fuente escrito en un lenguaje de alto nivel (por ejemplo PascalPascal es un lenguaje de programación desarrollado por el profesor suizo Niklaus Wirth y publicado en 1970. Su objetivo era crear un lenguaje que facilitara el aprendizaje de programación a sus alumnos, utilizando la programación estructurada y estructuración de datos. Sin embargo con el tiempo su utilización excedió el ámbito académico para convertirse en una herramienta para la creación de aplicaciones de todo tipo. , C++, Ada, ...) en código máquina (no es así siempre). Son más rápidos que los intérpretes pero presentan mayor dificultad a la hora de detectar errores.El compilador deriva su nombre de la manera en que trabaja, buscando en todo el código fuente, recolectando y reorganizando las instrucciones. Un compilador difiere de un intérprete en que el intérprete toma cada línea de código y la analiza y ejecuta mientras que el compilador mira el código por completo. Los compiladores requieren de un tiempo antes de poder generar un ejecutable, sin embargo los programas creados con compiladores se ejecutan mucho más rápido que un mismo programa ejecutado con un intérprete.

Diferencias entre compiladores e intérpretes
Los compiladores difieren de los intérpretes en varios aspectos:La comunicación
Un proceso cualquiera de comunicación está constituido por un EMISOR que envía INFORMACIÓNLa teoría de la información, también conocida como teoría matemática de la comunicación (mathematical theory of communication) o teoría matemática de la información, es una propuesta teórica presentada por Claude E. Shannon y Warren Weaver a finales de la década de los años 1940. Esta teoría está relacionada con las leyes matemáticas que rigen la transmisión y el procesamiento de la información y se ocupa de la medición de la información y de la representación de la misma, así como también de la capacidad de los sistemas de comunicación para transmitir y procesar información. La teoría de la información es una rama de la teoría matemática y de las ciencias de la computación que estudia la información y todo lo relacionado con ella: canales, compresión de datos y criptografía, entre otros. a través de un CANAL de transmisión, que es recibida por un RECEPTOR. Por tanto, se puede hablar de comunicación oral, escrita, etc., donde el canal será respectivamente el aire, el papel, etc. La información no es transmitida tal como la emitimos, sino que se utilizan unos CÓDIGOS comprensibles por el emisor y el receptor, y que se comunican mediante SEÑALES físicas. Los códigos serán el lenguaje utilizado y las señales son las las ondas electromagnéticas, sonoras, luminosas, etc. La utilización de códigos y señales precisa que la información sea CODIFICADA en la transmisión y DECODIFICADA en la recepción.
La información no es transmitida tal como la emitimos, sino que se utilizan unos CÓDIGOS comprensibles por el emisor y el receptor, y que se comunican mediante SEÑALES físicas. Los códigos serán el lenguaje utilizado y las señales son las las ondas electromagnéticas, sonoras, luminosas, etc. La utilización de códigos y señales precisa que la información sea CODIFICADA en la transmisión y DECODIFICADA en la recepción.
El objetivo de un proceso de comunicación es que la información que se envía sea idéntica a la que se recibe. Si falla cualquiera de los elementos que intervienen (transmisor, canal de transmisión o receptor), se producen pérdidas de información; para intentar evitarlo, se repiten los mensajes en su totalidad o en parte (redundancia), o se acompañan de códigos especiales (de control) que permitan reconstruirla en caso de error en el proceso.
Comunicación en la literatura
Conocer la lengua de la que se traduce no es el único requisito, hace falta otra herramienta indispensable: la experiencia personal, una enciclopedia propia. En el caso de los textos literarios, la experiencia personal no compartida del emisor y el receptor puede llegar a ser un obstáculo.
En la comunicación en el ámbito literario no se transmiten significados («metáfora del conducto») sino que se provocan significados en el destinatario y los significados provocados dependen de la experiencia de estos destinatarios. «El significado no es nunca objetivo y está siempre condicionado por la adquisición y el uso de un sistema conceptual. La experiencia física es personal, pero está mediatizada por conceptos acuñados socialmente, lo que hace posible la comunicación». Los contextos del que emite un mensaje y del que lo percibe no son los mismos, «el contexto es la aportación mental de quien interpreta un enunciado». Los constructos mentales constituyen el contexto de un enunciado, que se identifican dentro de esta línea cognitivista de acercamiento a la comunicación que estamos siguiendo con frames («conjunto de relaciones que establece una palabra con otras que aparecen en el mismo contexto y que se relacionan con la primera por su significado». El éxito de una oferta de información en el emisor dependerá por consiguiente tanto de la información que contenga su mensaje como de la información que evoque en su destinatario, de las experiencias e información compartidas que permitan la contextualización adecuada para desambiguar la información del texto en la manera propuesta y no de cualquier otra de entre las posibles (en el caso de un texto literario la ambigüedad es provocada por experiencia personal no compartida; en el caso de textos especializados la ambigüedad es provocada por conocimientos especializados —no personales— no compartidos). De aquí podemos deducir que en mensajes muy relacionados con las experiencias personales de los participantes en el acto de la comunicación es muy improbable que se «comunique» de forma plena dado que las experiencias personales siempre difieren en mayor o menor grado y que por lo tanto la información evocada en cada destinatario (cuando el destinatario es colectivo) será diferente; la comunicación especializada es más eficaz dado que la convencionalización social de la información transmitida es máxima.
En la comunicación en la literatura de carácter autobiográfico, de memorias o personal, se muestran, en grado extremo, todos los ingredientes que hacen peligrar las intenciones comunicativas del emisor o autor: el componente de la experiencia personal se da en su forma más intensa y la heterogeneidad de los destinatarios o lectores puede llegar a ser muy acusada. La intención comunicativa del autor puede llegar a sufrir una merma muy significativa porque el significado que asocia el autor del original a su texto se aparta mucho de los significados que evoca éste en una parte significativa de sus lectores.
La información más relacionada con la experiencia personal es la que se refiere a personas, a lugares, a momentos. Desambiguar en el texto toda la información que evocan estos elementos en el autor del original de una obra literaria de carácter personal exigiría enormes explicaciones, descripciones e interpretaciones, nunca suficientes, que habrían de resultar enormemente redundantes para los lectores con más experiencia compartida con el autor y probablemente tediosas para los lectores más distantes. La adición de información relacionada con la experiencia para asegurar la interpretación propuesta en la mayoría de los lectores supondría en todo caso una desvirtuación del género original que habría de desviarse inevitablemente de lo literario a una mezcolanza imposible entre lo literario o lo lírico y lo enciclopédico que le haría perder todo su valor al violar de forma grave las convenciones del género activas en sus destinatarios (para no malograr la traducción, los traductores tienen que refrenar su tendencia natural a explicarlo todo).
Se va a considerar la información sobre lugares, de tipo geográfico, en base a publicación: "Las herramientas del traductor. Ediciones del Grupo de Investigación Traductología. Facultad de Filosofía y Letras. Campus de Teatinos. 29071 Málaga".
La evocación de los lugares más cargados sentimentalmente para el autor del texto es riquísima para este autor (tanto en información factual como en sentimientos) y mucho menos rica o incluso vacía para el destinatario del texto. La relación entre sentimientos o impresiones estéticas que el autor del original quiere comunicar puede quedar opaca para el lector que no conoce los lugares descritos o evocados.
El caso que se va a comentar es de traducción. La traducción es otra forma más de comunicación, en particular en este caso entre individuos de culturas y de lenguas diferentes, de experiencias vitales por tanto con menos puntos en común habitualmente que las que unen a individuos de la misma lengua y cultura, a los que resulta más fácil comunicarse entre sí. Los problemas de comunicación indicados anteriormente para la comunicación en general y monolingüe en particular son los mismos para el caso de la traducción —en lo que se relaciona al menos con el tema tratado —, pero muy agravados por la proporción de experiencia no compartida; que en nuestro caso se va a concretar en la familiaridad con los lugares que describe el autor.
El texto elegido es una historia corta de Doris Lessing Doris Lessing (Kermanshah, 1919 - Londres. 2013) De soltera Doris May Tayler, que publicó también bajo el seudónimo de Jane Somers, fue una escritora británica, ganadora del Premio Nobel de Literatura en 2007. titulada «Lions, Leaves, Roses...» (The Story of a Non-Marrying Man and Other Stories (Leones, hojas, rosas... (La historia de un hombre no casado y otras historias,)), Harmondsworth: Penguin, 1975: 107-12). En este texto, Lessing describe un paseo por Londres, por Regent’s ParkEl Regent's Park (oficialmente The Regent's Park) es uno de los parques reales de Londres. Está en la zona norte del centro de la ciudad, parte en la Ciudad de Westminster y parte en el municipio de Camden. Fue diseñado por el arquitecto británico John Nash. . El paseo tiene lugar por el perímetro del Zoo de Londres, que se encuentra dentro de este parque. La superposición de perspectivas que disfruta en su paseo entre la parte del parque exterior al Zoo, el interior del Zoo y las colinas con viviendas exteriores al parque le permite a la autora sugerir una fusión entre estos tres ámbitos reales y también con otros ámbitos evocados (el Oriente del Hindu Kush y probablemente, por asociación, el de su vida en África) y con el ámbito imaginario de lo extraterrestre (con la introducción de un marciano que visita el parque). Como factor desencadenante de esta fusión en la que vegetales, animales, personas y extraterrestres se funden en un solo ser vivo, Lessing propone un momento de cambio estacional, un tránsito, el paso del otoño o verano tardío al invierno con el sol brillando por última vez.
La hipótesis de trabajo de la que se parte es que a los lectores del texto de Doris Lessing no familiarizados con Regent’s Park les va a resultar muy difícil compartir su experiencia y percibir lo que la autora quiere decir, que incluso la lectura del texto por destinatarios de otras culturas puede no producir suficiente sentido como para que éstos aprecien las intenciones de la autora. Una consecuencia de lo anterior es que el traductor del texto se va a enfrentar a una ardua tarea, no sólo en su papel de lector —que, aunque muy cualificado, también lo es— sino también en su papel de comunicador que debe intentar que los significados que evoca el texto en el lector de la traducción se acerquen lo más posible a las intenciones de la autora, incluidos los significados más puramente literarios y estéticos.
Para comprobar el grado en que se cumplen o se dejan de cumplir las hipótesis se ha seguido el siguiente procedimiento (según: Perdidos en Regent’s Park, ROBERTO MAYORAL).
- Se han seleccionado algunas partes del texto original en las que podía darse mayor ambigüedad.
- Se ha propuesto a dos traductores la traducción de los fragmentos escogidos tras haber leído la historia completa.
Uno de ellos es nativo español y otro es nativo británico sin especiales conocimientos de Regent’s Park. La intervención de este segundo traductor tiene como fin descartar el factor del desconocimiento de la lengua en la interpretación del texto. Estos traductores han hecho una primera traducción basándose únicamente en el texto (y en sus propias experiencias) como fuente de información. - Se ha proporcionado a los traductores información gráfica (fotografías y planos) de los lugares descritos en los fragmentos y se les ha propuesto realizar una segunda traducción al español.
- Se ha pedido a los traductores un comentario sobre la ambigüedad del texto original.
PLANOS FACILITADOS:

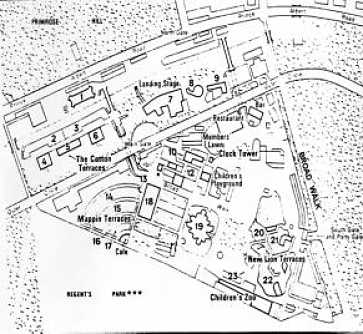
Comentario:
Regent’s Park contiene en su interior el Zoo de Londres. La autora inicia su paseo por un puente que salva el canal y que da a una de las entradas al Zoo. Inicia su tránsito por The Broad Walk, que es un paseo que linda con uno de los laterales del Zoo. En este costado se encuentran los espacios reservados para las cabras y los lobos, que se pueden ver desde el paseo puesto que solo están separados de éste por una alambrada metálica. La perspectiva desde el parque hace superponerse lo que hay en el paseo, lo que hay en el interior del Zoo y las viviendas de Primrose Hill, que se encuentran al fondo lindando con el Parque. El Parque tiene dos rotondas interiores, el Inner Circle y el Outer Circle. El Inner Circle alberga los Queen Mary’s Gardens, llenos de rosas.
Párrafo 1
Original:
The ornate bridge with its white pillars, its six iron lampposts, its balustrades, has at its ends flat oblong rectangles like pedestals, but empty. Here I paused to summon and set on watch my own personal lion.
Materiales gráficos facilitados:


- Traducción primera (traductor español):
El puente decorado con sus pilares blancos, sus seis farolas de hierro, sus balaustradas que terminan en forma de rectángulos planos como pedestales, pero vacíos. Aquí me detuve para evocar y mirar a mi león particular.
Traducción segunda (traductor español):
El puente decorado con sus pilares blancos, sus seis farolas de hierro, sus balaustradas que terminan en forma de rectángulos planos como pedestales, pero vacíos. Aquí me detuve para evocar y mirar a mi león particular.
Comentario del traductor español:
"Pensé que el león era una estatua grande, en reposo en el puente y mirando hacia el interior; de hecho supuse que debía haber más de un león (uno al principio y otro al final del puente, por ejemplo, delimitando el puente y como vigilando). Sigo pensando que no se puede referir a los cuatro leones que hay en las farolas. Ambiguo. Por la descripción que da puede ser uno de los leones que ve o imagina posando majestuosamente en el recinto del zoo".
Traducción primera (traductor británico):
El puente de estilo recargado con sus columnas blancas, sus seis farolas de hierro, sus balaustradas, tiene en los extremos plataformas rectangulares como pedestales, sólo que vacíos. En este punto me paré para convocar a mi propio león personal, al que mandé colocarse de guardia.
Traducción segunda (traductor británico):
El puente de estilo recargado con sus columnas blancas, sus seis farolas de hierro, sus balaustradas, tiene en los extremos plataformas rectangulares como pedestales, sólo que vacíos. En este punto me paré para convocar a mi propio león personal, al que mandé colocarse de guardia.
Comentario del traductor británico:
"No me imaginé que los leones formaban parte de los pedestales".
Original:
Already there are wild animals caged there, and right in its centre the roses in their circle are tamed and willing. The lion came off his dry hillside to crouch on St. Mark’s Bridge, facing inwards, a golden beast, his forepaws tucked under an eternal chest, his eyes green and solid, the eyes of a man, but man much more than any we know.
Comentario:
"La autora pone en contacto al león representado en la farola con los leones del interior y con los leones de sus recuerdos en África".
- Traducción primera (traductor español):
Hay animales salvajes enjaulados y justo en el centro, en forma de círculo las rosas crecen sumisas y serviciales. El león dejó su seca ladera para agazaparse sobre el puente de San Marcos, mirando hacia dentro, una bestia dorada, las patas delanteras bajo su pecho eterno, ojos verdes y firmes, los ojos de un hombre, mucho más hombre que los que conocemos.
Traducción segunda (traductor español):
Hay animales salvajes enjaulados y justo en el centro del parque, en una especie de anillo interior, las rosas crecen sumisas y serviciales. El león dejó su seca ladera para agazaparse sobre el puente de San Marcos, mirando hacia el centro, una bestia dorada, las patas delanteras bajo su pecho eterno, ojos verdes y firmes, los ojos de un hombre, mucho más hombre que los que conocemos.
Comentario del traductor español:
" La imagen que da es que las rosas, al igual que en los típicos jardines ingleses, están plantadas en espacios delimitados en forma de círculos, formando parte del diseño del jardín. También resulta ambiguo".
Traducción primera (traductor británico):
Allí los animales salvajes ya están encerrados en jaulas, y en todo el centro se encuentran las rosas en círculo, domesticadas y sumisas. El león se bajó de su monte seco para acurrucarse en el puente de San Marcos; la bestia dorada miraba hacia adentro, las patas delanteras dobladas debajo del pecho eterno, los ojos verdes y sólidos, los ojos de un hombre, un hombre más hombre que cualquiera que conozcamos.
Traducción segunda (traductor británico):
Allí los animales salvajes ya están encerrados en jaulas, y en todo el centro se encuentran las rosas en círculo, domesticadas y sumisas. El león se bajó de su monte seco para instalarse en el puente de San Marcos; una bestia dorada que mira hacia adentro, las patas delanteras ocultadas debajo del pecho eterno, los ojos verdes y sólidos, los ojos de un hombre, un hombre más hombre que cualquiera que conozcamos.
Comentario del traductor británico:
"No queda clara en el texto la realidad del Inner Circle y el Outer Circle".
Corpus lingüístico
Existen dos tipos de córpora lingüísticos: los generales y los de especialidad. Si entendemos corpus como un conjunto electrónico recopilado de textos hablados o escritos cuya finalidad es algún tipo de análisis lingüístico, los primeros se encargan de recoger todo tipo de géneros y son útiles para describir la lengua de una comunidad. Los corpus especializados, por otro lado, recogen material lingüístico que puede aportar información para la descripción de un área de especialidad o tema en particular.
El contar con un corpus de especialidad en un área determinada permite analizar y observar cuestiones relacionadas con el conocimiento de los expertos en esa especialidad; por ejemplo, podemos mencionar cómo se expresa el especialista y cómo escribe. También se pueden examinar rasgos textuales más refinados como el marcaje.
Corpus electrónicos
Recientemente el término corpus se considera como referido específicamente a una colección extensa de textos en formato electrónico, que han sido reunidos de acuerdo a criterios explícitos.
Como el texto bajo formato electrónico es mucho más fácil de recopilar y procesar que el impreso, un corpus bajo este tipo de formato suele ser mucho más extenso frente al elaborado en papel. La principal ventaja del formato digital es que puede ser manipulado por un ordenador u otro dispositivo electrónico. Algunos textos se crean directamente en formato electrónico (por ejemplo mediante un editor de textos o un programa reconocedor de voz). Otra ventaja es que se pueden compartir facilmente, ya sea a través de internet o mediante soportes de almacenamiento tales como llaves electrónics (pen drives), CD, … Si se disponen en papel es fácil digitalizarlos mediante programas de reconocimiento óptico de caracteresEl Reconocimiento Óptico de Caracteres es un proceso dirigido a la digitalización de textos, los cuales identifican automáticamente a partir de una imagen símbolos o caracteres que pertenecen a un determinado alfabeto, para luego almacenarlos en forma de datos, así se puede interactuar con estos mediante un programa de edición de texto o similar. Con frecuencia es abreviado en textos escritos en el idioma español, utilizando el acrónimo a partir del inglés OCR.
o programas reconocedores de voz.
Una vez que se ha creado el corpus, un tipo de programas conocidos como herramientas de análisis del corpus son habituales para ayudar el trabajo del traductor humano. Estas herramientas permiten al traductor acceder y mostrar la información contenida en el corpus, en diversas formas aunque siempre es responsabilidad del traductor analizar la información contenida en el corpus.
Finalmente es de destacar que un corpus no es una colección de textos aleatorios. Los textos se seleccionan de acuerdo a criterios explícitos, con la finalidad de ser usados como una muestra representativa de un lenguaje o un subconjunto del lenguaje. Por ejemplo, un traductor que elabora un corpus sobre electrónica, puede considerar la inclusión exclusiva de tópicos bajo la temática a considerar, que son de cierto tipo y en un intervalo de tiempo dado. De esta forma los traductores pueden elaborar diferentes córpora electrónicos para diferentes proyectos.
A su vez se pueden clasificar en base a algunas características generales, por ejemplo pueden ser monolingüe si tiene contenido en una sola lengua, bilingüe, multilingüe. Un corpus bilingüe que contiene texto fuente y su traducción se denomina habitualmente bitexto, aunque el término más habitual es corpus paralelo, que se puede emplear para describir colecciones bilingües y multilingües. Desafortunadamente hay alguna confusión con la palabra “paralelo”. Los textos escritos paralelos que usan convencionalmente los traductores consisten en textos que tienen la misma función comunicativa que el texto fuente, pero que están escritos originalmente en el lenguaje de destino; en otras palabras, no son traducciones del texto fuente, sino que son textos del mismo tipo y semejante tópico. Por otra parte corpus paralelo consiste de un texto fuente alineado con su traducción. El concepto de alineamiento es muy importante y se considerará más adelante.
Otros tipos de córpora incluyen los monolingües comparables y los bilingües comparables. Los primeros consisten de dos partes: una colección de textos que originalmente han sido escritos en el lenguaje A, y una colección de textos que han sido traducidos al lenguaje A desde otro lenguaje. Este tipo de corpus es habitual para investigadores interesados en estudiar la naturaleza del texto traducido, sin embargo es menos habitual en la práctica habitual de un traductor profesional. Los segundos son similares a los textos paralelos escritos por los traductores, ambas partes del corpus contienen texto del mismo tipo y sobre temática semejante, pero una parte contiene texto originalmente escrito en lengua A, mientras que la otra colección lo contiene en lengua B. Como las dos colecciones no tienen una relación texto fuente-texto destino, no se pueden alinear.
Por lo tanto, a pesar de que un corpus comparable bilingüe contiene potencialmente una gran riqueza de información útil para los traductores, es muy difícil de identificar y recuperar las secciones relevantes del texto de modo semiautomático. Una gran parte de la investigación se lleva a cabo en relación con el desarrollo y explotación de corpus comparables monolingües y bilingües, por lo que no pasará mucho tiempo antes de que las herramientas para ayudar a los traductores a explotar estos recursos estén disponibles de forma habitual.
Herramientas de análisis de corpus
Aunque hay algunas diferencias entre corpus impreso y electrónico, en muchos aspectos, el uso de un corpus electrónico no es tanto una salida radical frente a la utilización de un corpus impreso, sino un refinamiento que permite a los traductores aprovechar las ventajas ofrecidas por los medios de comunicación electrónicos. Para hacer esto, los traductores necesitan tener acceso a herramientas informáticas que les ayudarán a manipular e investigar el contenido del corpus. Estas herramientas permiten a los usuarios acceder y visualizar de forma útil la información contenida dentro de un corpus.
La mayoría de las herramientas de análisis de corpus por lo general incorporan una serie de características útiles que permiten a los usuarios generar y manipular la frecuencia de palabras, listas, concordancias y colocaciones. Estas características se describirán a continuación. También merece la pena señalar que muchas de las herramientas de análisis de corpus no fueron desarrollados específicamente para los traductores. Inicialmente, fueron destinadas a ser utilizadas por los profesionales de otros idiomas, incluidos los docentes de lengua extranjera y lexicógrafos. Sin embargo, son cada vez más populares entre los traductores y terminólogos, principalmente debido a que permiten a los usuarios tener acceso a los datos de frecuencia y ver los términos en una variedad de contextos al mismo tiempo, características que los diccionarios y corpus impresos no pueden proporcionar.
Listas de frecuencia de palabras
La característica más básica proporcionada por una herramienta de análisis de corpus es una lista de frecuencia de palabras, que permite a los usuarios descubrir la cantidad de palabras diferentes en un corpus y con qué frecuencia aparece cada una. Estas dos figuras se conocen como tipos y fichas (tokens). Para fines ilustrativos, supongamos que un corpus consiste en la siguiente frase:Esta frase contiene un total de trece palabras, por lo tanto, el corpus contiene trece tokens o fichas. Sin embargo, algunas de las palabras aparecen más de una vez (la, traducción), por lo tanto, el corpus contiene sólo once palabras diferentes, y estos se conocen como tipos. En la lista de frecuencia de palabras, los tipos se presentan en una lista y el número de fichas (el número de veces que aparece la palabra) se muestra junto al tipo. Esto se ilustra en la siguiente tabla.
Listas lematizadas
Algunas herramientas permiten tipos más sofisticados de manipulaciones, tales como la creación de listas lematizadas. Una simple lista de frecuencia de palabras puede procesar formas individuales de palabras. Esto significa que las palabras "traducir", "traduce" y "traducido" son tratadas como formas separadas, a pesar de que están relacionadas (son todas inflexiones del verbo "traducir"). A veces, puede ser útil para un traductor con el objetivo de poder agrupar las palabras relacionadas para obtener un recuento de la frecuencia combinada para el grupo de palabras en lugar de cuentas separadas para cada forma de palabra individual. El término "lema" se utiliza normalmente para describir una palabra que engloba y representa a todos las formas conexas. La siguiente tabla contiene un extracto de los veinte tipos más frecuentes (de un total de 29 589 tipos) de un corpus que contiene 183 832 fichas. Al observar a una lista de frecuencias, los usuarios pueden obtener rápidamente una idea general aproximada del corpus.
Listas de parada
Otro tipo de lista es una lista especializada de parada (stop), que contiene todos los elementos que el usuario desea que el equipo informático ignore. Por ejemplo, los traductores están habitualmente más interesados en las palabras que tienen un contenido semántico y están menos interesados en las palabras con una función gramatical, como artículos, conjunciones y preposiciones (en algunas lenguas pueden alcanzar el 30% de un texto). Si se genera una nueva lista de frecuencia de palabras para el mismo corpus, pero esta vez utilizando una lista de parada para ignorar las palabras con función gramatical, el extracto de los veinte principales palabras cambiará, como se ilustra en la tabla. Esta nueva lista de frecuencia deja más claro que el tema del corpus bajo consideración son los virus informáticos (en comparación con los virus que trata la medicina).
Concordancias
Los traductores no sólo tienen que ser capaces de entender el texto original, sino que además tienen que producir un texto de destino. Herramientas tales como diccionarios son muy útiles para la comprensión, pero con el fin de ser capaces de determinar cómo se pueden utilizar los términos, es más útil verlos en su contexto, y preferiblemente, en más de un contexto. Una segunda característica que es común a la mayoría de los análisis de corpus es una herramienta de concordancia. Algunas concordancias operan en los textos monolingües, mientras que otras funcionan en los textos bilingües, los cuales se describen por separado.
Concordancias monolingües
Una concordancia es una herramienta que recupera todas las ocurrencias de un patrón de búsqueda en particular en sus contextos inmediatos y los muestra en un formato fácil de leer. Algunas concordancias operan buscando a través de todo el corpus de principio a fin cada vez que se entra un patrón de búsqueda. Otros trabajan creando primero un índice de todas las palabras en el corpus junto con un registro de la ubicación de cada ocurrencia (por ejemplo, número de línea), como se ilustra a continuación de este párrafo. El índice debe ser creado antes de realizar cualquier búsqueda en un corpus dado, pero una vez creado, puede ser consultado en todas las búsquedas posteriores de elementos en ese corpus.Una vez que la búsqueda se ha realizado, los resultados se muestran para el usuario. El formato de visualización más común se conoce como visualización KWIC ("palabra clave en el contexto"). El término fue acuñado por primera vez por Hans Peter Luhn, el sistema se basa en un concepto llamado "palabra clave en los títulos" que se propuso por primera vez para las bibliotecas de Manchester (Reino Unido) en 1864 por Andrea Crestadoro. En una pantalla KWIC, todas las apariciones del patrón de búsqueda están alineadas en el centro de la pantalla. El alcance del contexto a cada lado del patrón de búsqueda es variable y a menudo puede ser especificado por el usuario.
Un programa "en línea" es Concordancier-corpus français (v.7), de la Université du Québec à Montréal, se puede acceder a través de la dirección http://lextutor.ca/conc/fr/, seguidamente se muestra el resultado de concordancias para la palabra Lait. La configuración usada también se visualiza.

Al igual que con las listas de frecuencia de palabras, estos contextos pueden ser ordenados en una variedad de formas, como el orden de aparición en el corpus, o por orden alfabético de acuerdo a las palabras anteriores o posteriores al patrón de búsqueda.
Las visualizaciones de pantallas KWIC no son el único tipo de visualización disponible. A menudo, el traductor tendrá que ver en un contexto más amplio, y se pueden generar concordancias que permiten navegar por la oración, párrafo, e incluso la totalidad del texto.
Además de la búsqueda exacta de la cadena, por lo general permiten patrones de búsqueda más sofisticadas, lo que posibilita funciones tales como búsquedas sensibles a mayúsculas y minúsculas (por ejemplo, para distinguir entre el "escéptico" y "Escéptico"); búsquedas con caracteres comodín, en los que se utiliza un carácter especial para representar a un carácter o más en una cadena de búsqueda (por ejemplo, "impr*" para recuperar "imprimir", "impresión", "impresora", "imprime", etc, o "crédul?" para recuperar los dos "crédulo" y "crédula"), y búsquedas con operadores booleanos (por ejemplo, AND, OR, NOT) u otras expresiones regulares. Otro tipo de búsqueda se puede dar en un contexto, en el que otro término debe aparecer dentro a una distancia, especificada por el usuario, del patrón de búsqueda (por ejemplo, los contextos en los que "impresora" aparece dentro de los cinco palabras en las proximidades de "cartucho").
Independientemente del tipo de patrón de búsqueda introducido, el beneficio del uso de líneas de concordancia como una fuente de evidencia lingüística es que revelan el contexto en el que se encuentran las ocurrencias individuales de palabras. Las opciones para ordenar y mostrar los datos pueden facilitar el proceso de observar y distinguir patrones de comportamiento lingüístico.
Concordancias bilingües
Una concordancia bilingüe es una herramienta que puede utilizarse para investigar el contenido de un corpus paralelo. Como se describió previamente, un corpus paralelo es un corpus que contiene una colección de texto fuente en lenguaje A alineado con su traducción al lenguaje B. Alineamiento es el proceso mediante el cual las secciones del texto de origen se vinculan con sus correspondientes traducciones. El alineamiento puede tener lugar en muchos niveles diferentes: texto, párrafo, oración, frase, subfrase, o incluso palabra. La mayoría de concordancias bilingües alinean los textos ya sea en el nivel de párrafo o de oración. Las alineaciones a nivel de texto son de muy de alto nivel para ser útiles para ayudar a los traductores a encontrar una equivalencia de una expresión particular, mientras que la alineación a nivel de palabra es muy difícil y propenso a errores debido a la falta de correspondencia de uno a uno entre la mayoría de los lenguajes naturales. Algunas concordancias bilingües más recientes, sin embargo, emplean medidas estadísticas con el fin de tratar de identificar posibles equivalentes de los términos de búsqueda específicos.Algunos programas tratan de hacer la alineación on the fly (durante la generación de concordancias bilingües), pero la mayoría de los programas separan los procesos de adaptación y generación de concordancia bilingües. Para la alineación de frases, se puede utilizar una herramienta de alineación automática, sin embargo, esto no es una tarea trivial, como cabría esperar. Existen algunas limitaciones, y los resultados dependen de la idoneidad de los textos para el alineamiento. Para lograr los mejores resultados, los textos fuente y destino deben estructura similar si no idéntica. El nivel más básico de funcionamiento de una herramienta de alineación automática es ir a través de los textos de forma secuencial, que une la primera frase del texto original con la primera del paralelo. Como las concordancias monolingües, las bilingües recuperan todas las ocurrencias de un patrón de búsqueda particular en sus contextos inmediatos. La mayoría de concordancias bilingües son bidireccionales, lo que significa que el patrón de búsqueda se puede introducir en cualquier lenguaje A, B, independientemente de cual sea el idioma fuente original. Algunas herramientas también permiten consultas bilingües en las que los términos de búsqueda son entre concordancias bilingües bidireccionales, lo que significa que el patrón de búsqueda puede ser entrado de forma simultánea en ambos idiomas. Muchas de las opciones de búsqueda disponibles en concordancias monolingües también están disponibles en concordancias bilingües (por ejemplo, las búsquedas con comodines). Una vez recuperada, las concordancias se suelen mostrar como segmentos formados por pares de frases o párrafos (dependiendo del nivel de la alineación empleado). Las secciones alineadas típicamente se muestran ya sea una junto a otra o una encima de la otra, como se muestra al final de este párrafo. También se pueden ordenar en forma similar a concordancias monolingües (por ejemplo, alfabéticamente de acuerdo con la palabra anterior o posterior al patrón de búsqueda).
Concordancia bilingüe
| Certains objets contiennent des virus qui peuvent endommager votre ordinateur. II est important de s'assurer que cet objet provient d'une source fiable. Etes-vous sin- que cet objet incorpore provient d'une source fiable? | Some objects contain viruses that can be harmful to your computer. It is important to be certain that this object is from a trustworthy source. Do you trust this embedded object? |
| ATTENTION: Les pages Web, les fichiers executables ou autres pieces jointes peuvent contenir des virus ou endommager votre ordinateur d'une autre facon. II est important de s'assurer que ce fichier provient d'une source sare. | WARNING: Web pages, executables, and other attachments may contain viruses or scripts that can be harmful to your computer. It is important to be certain that this file is from a trustworthy source. |
| Le formulaire de cet element n'a pas Me enregistre dans ce dossier ni dans la bibliotheque de formulaires de votre societe. Peut-etre preferez-vous ne pas executer les macros car cet element contient des macros susceptibles de contenir virus pouvant endommager votre ordinateur. | The form for this item has not been registered in this folder or in your company's forms library. Because this item contains macros, which could contain a virus harmful to your computer, you may not want to run the macros. |
Concordancias bilingües
| Checking for messages to clean up off the server...
Verification des messages A nettoyer depuis le serveur en cours... |
| Do you want to clean up your personalized settings for this program?
Souhaitez-vous supprimer vos parametres personnalises pour ce programme? |
| Unable to clean your free/busy information on the server
Impossible d'effacer les informations de disponibilité sur le serveur |
| Cleaner for Downloaded Program Files
Nettoyage des fichiers programmes telecharges |
Algunas concordancias bilingües han tratado de implementar características más sofisticadas. Por ejemplo, algunas herramientas tratan de identificar específicamente posibles equivalentes mediante el uso de medidas estadísticas. Por ejemplo, si el término de búsqueda "disk" se introduce con el Inglés como idioma de búsqueda, el proceso de concordancia bilingüe recupera todas las frases en las que aparece "disk", junto con las oraciones de destino correspondientes. La herramienta analiza los segmentos emparejados en un esfuerzo por determinar qué palabra(s) en las frases de destino aparecen con una frecuencia similar a la de "disk" en los segmentos de código fuente. Al usuario se le presentará una lista de candidatos que pueden ser potencialmente equivalentes. Por ejemplo, después de analizar todos los segmentos pares que fueron recuperados con el término de búsqueda "disk", el gestor de concordancias podrá proponer una lista de candidatos equivalente, que incluye los términos franceses "disque", "disquette", y "lecteur". El usuario puede seleccionar uno de estos candidatos y acceder a ver una pantalla KWIC. En este caso, la concordancia KWIC para los segmentos en inglés se muestra en la mitad superior de la pantalla y la concordancia KWIC para los segmentos en francés se muestra en la parte inferior de la pantalla. Identificadores de segmento (por ejemplo, S46, S17) se puede utilizar para indicar que segmentos de la lengua origen están emparejados con segmentos del lenguaje destino.
Concordancias bilingües
| S10 | The | disk | is full |
| S17 | A | disk | error has occurred during 1 write ope |
| S29 | The | disk | is write-prutocted. |
| S33 | Your hard | disk | is full or you may not have permis |
| S39 | An unexpected | disk | storage error has occurred. |
| S46 | r programs, check for | disk | space on the drive you are saving to a |
| S66 | A | disk | error occurred and you cannot open chi |
| S73 | Make sure the | disk | is not full or wrlte-protected and tha |
| S79 | deleted to make more | disk | space available. |
| S94 | The | disk | media is not recognised. |
| S96 | There is not enough | disk | space available on your computer to cr |
| S98 | eure there is enough | disk | space available on the drive. |
| S10 | le | disque | est saturé. |
| S17 | Une errour de | disque | s'est produite lors d'une opération |
| S29 | Le | disque | est protégé en écriture |
| S33 | Votre | disque | dur est peut-être saturé ou vous n'a |
| S39 | nduo se rapportant au | disque | de stockage s'est produite. |
| S46 | et vérifiez l'espace | disque | où vous voulez enregistrer votre fic |
| S66 | s'est produits sur le | disque | et vous ne pouvez pas ouvrir ce fich |
| S73 | Vérifiez que 1e | disque | n'est pas plein ou prótéqe en écritu |
| S79 | libérer de l'espace | disque | . |
| S94 | Le | disque | support n'est pas reconnu. |
| S96 | Espace | disque | insuffisant pour créer l'index sur v |
| S98 | urez vous de l'space | disque | du lecteur. |
Una ventaja de este tipo de búsqueda y visualización en pantalla es que los segmentos texto fuente y destino se pueden ordenar de forma independiente para revelar patrones en ambos idiomas. Por ejemplo, los segmentos de código texto fuente pueden ser ordenados alfabéticamente de acuerdo a la palabra que sigue a la palabra de búsqueda, mientras que los segmentos de texto destino podrían ordenarse alfabéticamente de acuerdo a la palabra que precede a la palabra de búsqueda. Como se muestra seguidamente, en la ventana del idioma de origen (por ej. inglés), las ocurrencias de la palabra "disk" se han ordenado alfabéticamente de acuerdo con la siguiente palabra, que revela los patrones como "disk error" y "disk space". Mientras tanto, en la ventana de la lengua destino (por ej. francés), las ocurrencias del equivalente seleccionado "disk" han sido ordenados alfabéticamente de acuerdo a la palabra anterior, lo que revela el patrón de "espace disque". A pesar de que los segmentos en las dos ventanas ya no coinciden cronológicamente (por ej., el primer segmento que aparece en la ventana texto fuente ordenado, no es la traducción equivalente del primer segmento que aparece en la ventana de la lengua destino odenado), los usuarios pueden referirse a los números del segmento identificador para establecer qué segmentos pertenecen a la misma unidad de traducción.
Concordancia bilingüe
| S17 | A | disk error has occurred during a write oper |
| S66 | A | disk error occurred and you cannot open thi |
| S10 | The | disk is full |
| S29 | The | disk is write-protected |
| S73 | Make sure the | disk is not full or write-protected and tha |
| S33 | Your hard | disk may be full or you may not have permis |
| S94 | The | disk media is not recognized. |
| S46 | programs, check for | disk space on the drive you are saving to a |
| S79 | deleted to make more | disk space available. |
| S96 | There is not enough | disk space available on your computer to cr |
| S98 | sure there is enough | disk space available on the drive. |
| S39 | An unexpected | disk storage error has occurred. |
| S39 | ndue se rapportant au | disque de stockage s'est produite |
| S17 | Une erreur de | disque s'est produite lors d'une operation |
| S96 | Espace | disque insuffisant pour creer l'index sur v |
| S46 | et verifiez l'espace | disque on vous voulez enregistrer votre tic |
| S79 | r liberer de l'espace | disque. |
| S98 | urez-vous de l'espace | disque du lecteur. |
| S10 | Le | disque est saturé. |
| S29 | Le | disque et protégé en écriture, |
| S66 | s'est produite sur le | disque et vous ne pouvez pas ouvrir ce fich |
| S73 | Verifiez que le | disque nest pas plein ou protégé en ecritu |
| S94 | Le | disque support nest pas reconnu. |
| S33 | Votre | disque dur est peut être saturé ou vous n'a |
Consulta bilingüe
| The system cannot find the drive specified. | Lecteur introuvable |
| Close other programs check for disk space on the drive you are saving to and on the drive containing you folder, and the save again. | Fermez d'autres programmes et verifiez l'espace disque où vous voulez enregistrer votre fichier, et le lecteur où se trouve le dossier, puis réengistrez votre travail. |
| Make sure there is enough disk space available on the drive that containts you folder. | Assurez-vous de l'espace disque du lecteur contenant le dossier. |
| Available space on drive: 23 MB. | Espace disponible sur le lecteur: 23 Mo. |
| The drive "Y" is not valid. | Le lecteur "Y" n'est pas valide. |
| Enter a valid drive letter. | Tappez une lettre de lecteur valide. |
| The selected disk drive is not in use. | Le lecteur sélectionné n'est pas en service. |
| The floppy disk in drive A is not formatted. | Le disquette dans le lecteur A n'est pas été formatée |
| Drive Y does not exist or is not accesible. | Le lecteur Y n'existe pas ou n'est pass accesible |
| Make sure you entered the correct drive | Vérifiez que vous avez tapé le bon nom de lecteur |
Colocaciones
Muchas herramientas de análisis de corpus también tienen capacidad para calcular las colocaciones, que son patrones característicos de coocurrencias de palabras. Las colocaciones son generalmente consideradas como palabras que "van de la mano" o se "encuentran en compañía de otra". Una descripción más técnica es que las colocaciones son las palabras que aparecen juntas con una mayor probabilidad que si fuera debido al azar. Porque el lenguaje no es aleatorio, ciertas palabras tienden a juntarse (clusters), y algunos de estos grupos forman colocaciones. Los generadores de coubicación en herramientas de análisis de corpus, por lo general determinan si dos palabras son colocaciones, mediante la comparación de los patrones actuales de coocurrencia de pares de palabras frente los patrones que se podrían haber esperado si las dos palabras se distribuyeran aleatoriamente a lo largo del texto.
Una fórmula comúnmente utilizada para determinar la probabilidad de que dos palabras sean colocaciones es una fórmula de información mutua (MI). La puntuación de MI entre cualquier par de palabras dadas compara la probabilidad de que dos palabras que aparecen juntas como una unidad (debido a que "van de la mano") frente a la probabilidad de que su coocurrencia sea simplemente un resultado del azar. Por ejemplo, en la frase "The virus signature has not been recorded," las palabras "virus" y "signature" se presentan juntas, ya que son parte de una unidad multipalabra. Por el contrario, en la frase "The virus that is on my computer is destructive,", las palabras "virus" y "that" se presentan juntas, pero no lo hacen bajo ninguna relación especial; su yuxtaposición es más un resultado del azar. Si dos palabras están fuertemente conectadas, tendrán una puntuación MI alta. Si tienen un nivel bajo de coocurrencia - aparecen por separado con más frecuencia que juntas- su puntuación MI será baja (posiblemente incluso negativa). Esto significa que los pares con niveles altos de MI son más propensos a ser colocaciones que las palabras con puntuaciones MI bajas. Hay, sin embargo, algunos inconvenientes asociados con la fórmula MI. En primer lugar, se asume que las palabras se producen en diferentes eventos totalmente independientes, mientras que la lengua está en realidad llena de dependencias (por ejemplo, debido a los requisitos gramaticales). En segundo lugar, MI requiere un número mínimo de coocurrencias (por lo general alrededor de cinco) dentro de un corpus con el fin de ser válida.
Una vez calculadas, las colocaciones se pueden mostrar en orden alfabético o de frecuencia en el ranking que muestra la palabra nodo (el patrón de búsqueda) y las posiciones a la izquierda y derecha del nodo en el que las colocaciones se producen. Las colocaciones no necesariamente aparecen lado por lado, a veces hay una o más palabras que intervienen. Muchos generadores de colocación puede calcular colocaciones que se encuentran dentro de un rango especificado por el usuario. Por ejemplo, como se ilustra en la siguiente tabla, además de aparecer en la posición inmediatamente antes o después del nodo de búsqueda, una colocación puede aparecer varios lugares a la izquierda o a la derecha.
| Node and collocate juxtaposed | Node and collocate separated by one intervening word | Node and collocate separated by two intervening word |
|---|---|---|
| infected file | infected backup file | |
| infected attachment | infected email attachment | |
| clean infected disk | clean an infected file | clean all infected disketes |
| infected document | infected Word document | |
| infected disk | infected floppy disk | infected writable optical disk |
| infected system | infected computer system | infected network operating system |
Anotaciones y marcas
El proceso del corpus indicado se ha descrito usando córpora "crudos". Sin embargo, es posible codificar información adicional en el corpus, y esta información puede ser de naturaleza lingüística o no lingüística. Esta adición de información lingüística se conoce habitualmente como anotación mientras que la adición de información no lingüística se conoce habitualmente como marcado de corpus. La decisión acerca de cuando un corpus debe ser o no anotado y/o marcado depende del proyecto bajo consideración. Se considerará brevemente puesto que puede involucrar el uso de herramientas automáticas.
Un tipo popular de anotación lingüística se conoce como "anotación sintáctica", en la que cada palabra en el corpus tiene su parte asociada de la palabra especificada con las etiquetas. Desafortunadamente no hay un estándar para las etiquetas, como se muestra en la siguiente tabla, algunas etiquetas son notaciones muy generales como por ejemplo "verbo", "nombre", mientras que otras son más específicas como "verbo imperativo", "sustantivo plural común". Los signos de puntuación también se pueden considerar análogamente.
Anotación sintáctica
| Palabra etiquetada | Conjunto de etiquetas | |
| Anotaciones usando etiqueta general | Scan<VB> for <PREP> viruses <NN> regularly <ADV>. <PUNC> | VB=verbo |
| PREP=preposición | ||
| NN=nombre | ||
| ADV= adverbio | ||
| PUNC= símbolo puntuación | ||
| Anotaciones usando etiquetas más específicas | Scan <VBO> FOR <II> viruses <NN2> regularly <RR>; <YSTP> | VBO=verbo imperativo |
| II=preposición general | ||
| NN2=nombre plural común | ||
| RR=adverbio | ||
| YSTP=punto final |
Otro tipo de de anotación lingüística, conocido como anotación semántica, se puede usar para distinguir entre los distintos significados de una palabra. Se llaman homónimas las palabras que muestran el mismo aspecto pero que tienen distinto significado al aparecer en contextos diferentes. Por ejemplo "banco" hace referencia a: 1) institución financiera o 2) Conjunto de peces que van juntos en gran número. Se debe utilizar una anotación semántica (por ej.: banco1 frente banco2) para distinguir entre los diferentes sentidos de una palabra.
La ventaja de disponer de un corpus con anotación lingüística es que permite a los usuarios focalizarse en sus búsquedas más estrechamente. Por ejemplo, un traductor podría desear recuperar todas las apariciones de la palabra "test" cuando aparece como verbo, pero no como sustantivo, o todas las instancias de la palabra "banco" cuando aparece en el sentido 1 pero no en el sentido 2. Dichos patrones de recuperación podrían no ser posibles en un corpus sin anotaciones.
Una forma de añadir información no lingüística a un corpus puede realizarse marcando las diferentes secciones estructurales del texto (por ej.: título, subtítulo, sentencia, párrafo sección, capítulo). De esta forma es posible preguntar al ordenador para recuperar apariciones de un patrón dado de búsqueda, por instancia como puede ser el título del texto. Otra información no lingüística que se puede añadir al corpus son: fecha de publicación, tipo de texto, campo de temática, autor de la traducción y otros detalles relacionados. Esta información se ha de añadir manualmente.
La ventaja de un corpus sin añadidos manuales (raw) es que es fácil y rápido de elaborar. Las anotaciones y marcas requieren una gran inversión inicial de tiempo, aunque posibilitan las búsquedas más específicas. Si se tiene en mente el proceso más rápido y general, es habitual que se use el proceso a partir de un texto, mediante escaneado, alineamiento, tagging; aunque el resultado tiene bastante probabilidad de incorporar errores de forma que se hace imprescindible la posterior depuración manual.
Etiquetadores morfosintácticos
| Programa | Tipo | S .O. | Distribución | Lenguas |
| CLAWS | Híbrido | Unix y Windows | Comercial y gratis en línea | Inglés |
| Freeling | Híbrido | Linux, Unix, Windows | Comercial y gratis en línea | Catalán, español, gallego, italiano, inglés |
| TreeTagger | Estadístico | Linux, Mac OSX y Windows | Gratuito | Independiente de la lengua |
| Connexor | En línea | Demo gratuita | Varias lenguas |
Beneficios y desventajas de trabajar con herramientas de análisis del corpus
Las herramientas de análisis del corpus se han usado desde hace tiempo por los profesionales del lenguaje, tales como profesores de lenguas extranjeras, lexicógrafos y traductores. Su empleo se ha incrementado progresivamente dadas las ventajas de dichas herramientas. Sin embargo las ventajas deben ser contrastadas cuidadosamente frente a las desventajas antes de tomar una decisión sobre el uso de una de estas herramientas.