|
|
PODER Y LENGUAJE EN BRUISED HIBISCUS, DE
ELIZABETH NUNEZ:
ANÁLISIS
LITERARIO
A
TRAVÉS DE LA HERRAMIENTA INFORMÁTICA WMATRIX
Audy
Yuliser Castañeda Castañeda
Universidad
Pedagógica Experimental Libertador, Instituto Pedagógico de Caracas. Venezuela
Rosa
López de D'Amico
Universidad
Pedagógica Experimental Libertador, Instituto Pedagógico de Maracay. Venezuela
RESUMEN
En esta
investigación se aborda el tema del poder y el lenguaje, tal y como se
manifiesta en el mundo ficticio creado en la novela Bruised Hibiscus
(Cayenas Magulladas), de la escritora trinito-baguense Elizabeth Nunez. Para
ello se realizó una indagación documental con la inclusión de los conceptos de hegemonía,
de Gramsci, así como de sustentos teóricos desde la perspectiva lingüística,
con los planteamientos de Halliday y de Hoey. A través de la herramienta
informática WMatrix, generada en la Universidad de Lancaster, Reino Unido, se
procesó vía digital el texto completo de la novela seleccionada, lo cual
proporcionó información de tipo cuantitativo que sirvió de evidencia para
corroborar las intuiciones que como lector surgieron a partir del contacto con
el texto literario. El mundo ficticio creado en Bruised Hibiscus refiere
a una re-visión de la historia de países postcoloniales como Trinidad y Tobago,
su fragmentación por razones étnicas, de género, y culturales, que aún permean
el imaginario de la región.
PALABRAS
CLAVE: WMatrix, literatura postcolonial, Elizabeth Nunez, Caribe de habla
inglesa, Bruised Hibiscus, lenguaje, poder, hegemonía.
ABSTRACT
In this study we deal with the topic of power and language, as it is
evident in the fictitious world created in Trinidarian writer Elizabeth Nunez’s
novel Bruised Hibiscus. In order to achieve our goal, we conducted a
documentary research that focuses on Gramsci’s notion of hegemony, and
linguistic theories as those by Halliday and Hoey. WMatrix, a software created
in
PALABRAS CLAVE: WMatrix, postcolonial
literature, Elizabeth Nunez, English-speaking
INTRODUCCIÓN
Con el fin de analizar el fenómeno histórico-social conocido como el
colonialismo, con frecuencia se hace referencia a la obra de Antonio Gramsci,
en particular su concepto de hegemonía – un término que describe cómo
las clases dominantes obtienen y mantienen el poder sobre la clase subalterna,
a través de una combinación entre coacción y consentimiento. Dicho concepto se
ha utilizado en las teorías sobre los discursos coloniales para explorar cómo
opera el lenguaje con el fin de “hacer que las personas colonizadas acepten
su rango de inferioridad dentro del esquema colonial” (McLeod 2000, p. 18).
El colonialismo puede operar
persuadiendo a las personas para que internalicen la lógica de este sistema de vida,
y para que acepten el conjunto de valores coloniales – un proceso que en los
estudios de corte postcolonial suele identificarse con el término de colonización
mental. El lenguaje es una parte fundamental de este proceso, ya que éste
proporciona los términos con los cuales se puede percibir y comprender al
mundo. El sujeto colonizado – representado como el otro, inferior en el
discurso imperialista – percibe el mundo, así como su lugar en él, en términos
coloniales. A través del uso del lenguaje del conquistador, el sujeto
colonizado perpetúa los valores y supuestos que lo mantienen oprimido.
Gramsci, desde una perspectiva marxista, utiliza el término clases
subalternas para describir aquellos grupos “subordinados por la hegemonía y
excluidos de todo rol significativo en un régimen de poder” (Holden, 2002,
p.38). Según Gramsci, para que un grupo pueda obtener y mantener el poder debe
establecerse una forma de control político y social, que combina la
fuerza física o la coacción con la persuasión intelectual, moral y
cultural o el consentimiento (Ransome, 1992, p. 135). Gramsci (en Hoare
y Smith, 1971, p. 45) afirma que “la supremacía de un grupo social se hace
manifiesta en dos formas, ya sea como dominación o como liderazgo
intelectual y moral. La coacción social, el control, o la dominación,
opera normalmente a través del Estado, mientras que el control consensuado
deriva de aquellas instituciones y prácticas asociadas a la sociedad civil, por
ejemplo, la Iglesia, la educación, y los partidos políticos (siempre y cuando
éstos no sea simpatizantes del gobierno al mando en un momento determinado).
Cabe destacar que el Estado
y la sociedad civil no siempre operan como dos extremos opuestos, ya que las
formas de control social a través de la coacción o del consenso
pueden operar en ambas esferas. Ransome (1992) proporciona un ejemplo de cómo
la autoridad que ejerce la coacción puede influir en las prácticas
religiosas de la sociedad civil:
|
En la práctica religiosa (…) la autoridad coercitiva opera en una dimensión espiritual y por
lo tanto no es violenta desde un plano físico. Para un individuo disidente,
sin embargo, la amenaza de una posible exclusión social podría en efecto ser
tan debilitante como el castigo físico.
(p. 143) |
Uno de los canales principales a
través de los cuales opera la hegemonía es el lenguaje, en el contexto
educativo, religioso, y en los medios de comunicación, por ejemplo. Así, la hegemonía
es una forma de ideología, un método de control social logrado a través del consenso,
en el cual las clases dominantes procuran mantener el control sobre las mentes
y almas de las clases subordinadas, persuadiendo a éstos últimos para que voluntariamente
acepten y asimilen las normas y valores de los grupos al poder.
Gramsci se refiere al subalterno
como un individuo que está subordinado por una visión de mundo hegemónica, y
excluido de toda posibilidad de hablar con voz propia. En los estudios de corte
postcolonial el término se ha utilizado para identificar a aquellos individuos
o grupos dominados u oprimidos por un Otro más poderoso, dentro de una
sociedad colonizada. Sin embargo, hay quienes, como Greenstein, argumentan el
carácter no necesariamente dicotómico de la relación entre el opresor y el
oprimido, ya que dentro de un pueblo colonizado pueden existir “diversos
discursos de poder y resistencia” (citado en Loomba, 1998, p. 239).
Para complementar las ideas de
Gramsci, caben mencionar algunas nociones sobre la gramática
sistémico-funcional de Halliday (2004), así como algunos planteamientos de Hoey
(2006) sobre la preparación léxica (lexical
priming). Tanto Halliday como Hoey ofrecen un marco de análisis a través
del cual se puede analizar críticamente la voz del subalterno. Ambas teorías surgen desde extremos
diferentes de la escala léxico-gramatical y dan luces sobre cómo la hegemonía
ejerce su función. Halliday (2004) le da prioridad a los sistemas gramáticos,
según lo cual el emisor de un mensaje está limitado por el registro, teniendo que ejercer una función comunicativa
sobre la base del contexto de la situación. En contraste, Hoey (2006) le da
prioridad al aspecto léxico, según lo cual el emisor del mensaje se preparará
para utilizar ciertas unidades léxicas en ciertos contextos, de maneras
determinadas.
Según Halliday, el significado se
encuentra en cada selección u opción elegida, la cual se evidencia en el uso
del léxico y la gramática. Para transformar la experiencia en significado, el
emisor de un mensaje tendrá que seleccionar entre una red de sistemas
disponibles, y las opciones elegidas dependerán, en gran medida, de cómo se
construye el evento. Los aspectos léxico-gramaticales de un texto, entonces,
revelan algo sobre cómo el individuo construye los eventos e interpreta la
realidad; también podrían evidenciar algo sobre el lenguaje de la hegemonía
– los procesos discursivos que posicionan a los sujetos y construyen las
experiencias. Para Hoey, en cambio, la noción de selección u opción es
problemática. Para él, los individuos no seleccionan a partir de una red de sistemas,
sino que están preparados para usar el lenguaje de cierto modo, en
ciertos contextos. El término preparación (priming, en inglés) se
refiere a cómo las palabras tienden a atraer ciertos ambientes gramaticales y
colocaciones como resultado de “los efectos acumulativos de los encuentros
personales e irrepetibles de una persona con un mundo particular” (p. 13). Es
decir, ya que las experiencias lingüísticas de un individuo son únicas, también
lo serán sus preparaciones.
Por supuesto que para evitar que
dichas preparaciones individuales no varíen demasiado de un individuo a
otro, y ello impida la comunicación, existen, en cada cultura, según lo concibe
Hoey, mecanismos de armonización (2005, p. 181), es decir, mecanismos
para asegurar que exista consistencia entre las preparaciones de cada
individuo. Esta visión de armonización parece complementar a la noción
de hegemonía propuesta por Gramsci, y viene a representar el ejercicio
del poder sobre el lenguaje de los otros a través de medios consensuados. El
argumento central entonces, es que el individuo, al utilizar el lenguaje tal
cual como está preparado para ello, refuerza efectivamente a las
estructuras de poder que lo oprimen, formulando así la manera de concebir y
experimentar al mundo que lo rodea.
Análisis de textos asistido por el computador
Los diversos enfoques discutidos en
las secciones anteriores, sobre hegemonía, la selección a partir de una
red de sistemas o alternativas, y la preparación lingüística,
resultan incompletos si no se les acompaña con algunos fundamentos de la Lingüística de Corpus, aplicables en el estudio del discurso literario, haciendo énfasis en
el uso de softwares o paquetes informáticos. Esto es especialmente cierto en
los casos de estudios de textos muy extensos, donde las herramientas
informáticas pueden agilizar el proceso de búsqueda de información para el
análisis e interpretación.
Los procesos de investigación cualitativa construyen o generan grandes
cantidades de registros de texto, o narrativas que requieren de clasificación.
Los antropólogos han sido grandes maestros en el registro y la organización de
los textos que crean a partir de trabajo de campo prolongado. Es precisamente
la necesidad de organizar tal cantidad de información la que han resuelto a
través del método etnográfico y de la utilización de técnicas de registro y
análisis acordes a los marcos conceptuales de los que parten los autores. Para
ello se han auxiliado de los recursos que están a la mano, ya sea la pluma y el
papel, la máquina de escribir o la computadora.
Antes del 2000, hubo esfuerzos previos para lograr
codificar la información a través de bases de datos tales como Lotus, Dbase III
plus e incluso para algunos autores el Access es una opción válida. Para
organizar la información en pocas categorías. El Atlas Ti de Alemania (ahora en
versión 6.0) o el grupo de Qualitative Research Software (QSR) 1995, con
antecedentes en la creación del Nudist (1981), después Nvivo 2 y ahora Nvivo 8
o 9 (en revisión) o el Xsight son la nueva generación de programas que permiten
analizar textos que provienen de transcripciones de audio, videos (imagen)
fotografías, y que responden a diversas necesidades de clasificación y análisis
de tal forma que quienes tienen marcos conceptuales y metodológicos diversos
pueden hacer uso de este recurso con diversas formas por su flexibilidad.
En ninguno de los programas existentes, el análisis de la
información lo realiza un programa de cómputo, sino que este es una herramienta
muy útil que agiliza el manejo de la información que logra hacer visible los
esquemas y definiciones conceptuales, y con ello, permite a los docentes y
alumnos comprender mejor la forma en que se está trabajando la información, o
bien, les permite a integrantes de dos o más disciplinas, analizar el mismo
texto con miradas profesionales diversas y después construir un análisis multi
o interdisciplinario. Pero si bien, el programa no hace por sí mismo el
análisis, es una herramienta útil que a partir de la experiencia del
investigador, (su formación teórica y metodológica) le permite avanzar en
términos de rigor y manejo de grandes cantidades de textos.
En la actualidad
existen numerosos programas de computación que facilitan el proceso de análisis
de la información. Entre ellos se hará énfasis en WMatrix, que es el software que se comentará más adelante con ejemplos a
partir de una novela escrita por Elizabeth Nunez, Bruised Hibiscus.
Para la
investigación cualitativa asistida por computadora, es importante recordar que
los programas que existen y que seguirán surgiendo en el mercado, no sustituyen
el trabajo analítico del investigador.
Al respecto, también es importante considerar las tareas cognitivas que
se requieren de quien investiga para llevar a cabo con éxito una investigación
de este tipo. Morse (1994) menciona cuatro procesos cognitivos inherentes al
análisis de datos, los cuales aparecen íntegros en todos los métodos
cualitativos: (a) la comprensión; (b) la síntesis; (c) la teorización; y (d) la
recontextualización. Las herramientas informáticas no aseguran en sí mismas el
rigor, la validez, o la confiabilidad de la investigación. La construcción del
dato cualitativo está compuesta por los procesos cognitivos antes señalados,
además por la relación viva y
existencial con los participantes.
La
Lingüística de Corpus, La Estilística y el Análisis de Textos Literarios
En este
apartado se considerará la utilidad de incluir procedimientos de análisis sobre
la base de los planteamientos presentados por la Lingüística de Corpus y la
Estilística, en particular en cuanto se refiere al discurso literario. El término discurso se aplica aquí en
su uso más general, para referirse a “las palabras en el texto literario (…) en contraposición a su línea argumental
(Murfin y Ray 2003, p. 113).
El área
del discurso literario se relaciona con otras subáreas, incluyendo la crítica
literaria y la estilística. La tarea de
quien realiza crítica literaria es interpretar y evaluar un texto literario –
tarea que por demás, implica examinar el lenguaje utilizado – mientras que la
quien practica estilística analiza y describe los rasgos lingüísticos de un
texto literario e interpreta sus hallazgos de la manera más explícita posible
(Short, 1996, p. 2). De esta manera, ambas subáreas están íntimamente
relacionadas y con frecuencia se solapan en sus funciones. Es por esto que esta sección se enfoca en el
área de la Estilística y especialmente, en cómo la Lingüística de Corpus puede
contribuir a sistematizar los hallazgos.
En
primer lugar, se caracterizan los diferentes enfoques de la Estilística, que se
pueden clasificar en dos grupos principales: (a) enfoques textuales; y (b)
enfoques contextuales. Seguidamente se
discute cómo la Lingüística de Corpus puede contribuir al área de la
Estilística. Finalmente, se delinea el
papel de la Lingüística de Corpus en el estudio del discurso literario,
haciendo énfasis en el uso de software o paquetes informáticos, tales como
WMatrix.
Enfoques en la Estilística
En su
sentido más amplio, la Estilística estudia el lenguaje de la literatura, “un
campo de indagación empírica, en la cual se usan los hallazgos y técnicas de la
teoría lingüística para analizar textos literarios” (Wynne 2005, p. 1). Las
teorías que se relacionan con la semántica, la sintaxis, la morfología y la fonética
con frecuencia permiten identificar los diferentes rasgos de un texto literario
(Bradford 1997, p. xi). La Estilística examina el estilo de un texto,
definido por sus componentes lingüísticos y sus efectos en el lenguaje dentro
del texto. En este sentido Bradford
(1997) distingue al menos dos enfoques a la Estilística, textuales y contextuales,
que se describen a continuación.
Los
enfoques textuales se centran en la diferencia estructural existente
entre los textos literarios y no literarios, y destacan la distinción entre lo
que es el lenguaje literario en contraposición con el lenguaje cotidiano
(Rivkin y Ryan 2004, p. 3). Bradford (1997) comenta al respecto que los rasgos
estilísticos de un texto literario en particular son vistos como “el producto
de una unidad e integridad empírica” (p. 13). Así el texto es visto como una
obra de arte autónoma que puede ser examinada explícita, objetiva y
científicamente, con independencia de sus elementos socio-históricos,
culturales o intertextuales. Los mecanismos
estilísticos se consideran como “una propiedad inherente al texto literario,
que excluye al lector” (Weber 1996, p. 1).
Los enfoques contextuales a
la Estilística conciben al estilo literario como “formado e influenciado
por sus contextos” (Bradford 1997, p. 73). El estilo no es inherente al
texto, sino más bien “un efecto producido en, por y a través de la interacción
entre el texto y sus lectores” (Weber 1996, p. 3). El estilo entonces,
se ve afectado por la interacción entre el autor, el contexto de producción del
autor, el texto, el lector, y el contexto de recepción del lector. Quien realiza Estilística bajo esta
concepción examina el texto literario como un producto del contexto en
el cual se produjo. Los mecanismos
estilísticos se ven influenciados por, y reflejan además, ideologías, creencias
y suposiciones sociales, culturales y políticas. Estos enfoques centrados en el
contexto toma elementos y procedimientos a partir de la Lingüística
Sistémico-Funcional, la Teoría de las Metáforas, la Teoría de los Actos de
Habla, entre otras disciplinas, las cuales definen los rasgos formales de un
texto como “un reflejo, imitación o correspondencia con una realidad que existe
con independencia del lenguaje” (Weber 1996, p. 6).
Enfoques de la Estilística Basados en la Lingüística
de Corpus
Como se
señaló anteriormente, la Estilística y la Lingüística de Corpus comparten
algunas semejanzas. Ambas son áreas de
indagación empírica que se apoyan en evidencia lingüística hallada en el texto
literario. No obstante este interés
común, el papel de la Lingüística de Corpus en el área de la Estilística
permanece no sin ciertas ambigüedades. Wynne (2005) señala que aún existe, pese
a la existencia de algunos estudios realizados que destacan los beneficios potenciales
del uso de técnicas de la Lingüística de Corpus en el estudio del estilo
literario, “un uso limitado de los corpora, o de las técnicas de la Lingüística
de Corpus para el análisis literario” (p. 1).
La posición asumida aquí es que la
preocupación por que las técnicas más tradicionales de análisis se vean
desplazadas por herramientas informáticas no está sólidamente fundamentada, ya
que el trabajo realizado hasta ahora con el uso de corpora y software informático
se han utilizado para complementar y no para reemplazar la intuición del
lector. Las herramientas provenientes de
la Lingüística de Corpus se han utilizado para comprobar hipótesis, verificar
una práctica estilística intuitiva, y para construir más conocimiento a partir
del ya existente. Se favorece, en este
sentido, la práctica de lo que varios estudiosos, entre ellos Baker (2006),
describen como triangulación, vale decir, “un enfoque a la investigación
más ecléctico, donde diversas metodologías puedan combinarse y reforzarse unas
a las otras” (p. 16). No obstante, se necesita más investigación sobre la
posible contribución de la Lingüística de Corpus al estudio del discurso
literario.
El paquete
informático WMatrix
A
continuación se describe en qué consiste el paquete informático WMatrix,
escogido como herramienta para sistematizar y complementar el análisis
contemplado para la consecución de los objetivos propuestos para esta
investigación.
En el sitio web de WMatrix, http://ucrel.lancs.ac.uk/wmatrix/, se describe como una herramienta informática para el análisis y
comparación de textos que provee una interfaz a las herramientas de anotación
USAS y CLAWS, así como a métodos de la Lingüística de Corpus tales como listas
de frecuencias y concordancias. Elabora
listas de palabras claves incluyendo categorías gramaticales y dominios
semánticos.
El etiquetado de las palabras según su función gramatical
es conocido en inglés como POS tagging (Part of Speech
tagging), que como se mencionó antes, lo ejecuta el software CLAWS en WMatrix.
Ejecuta la tarea automática de anotación de categorías sintácticas para cada
palabra en un texto; esto es de gran importancia para el procesamiento de
textos con ayuda de software especializado, para clasificar cada palabra y
poder desarrollar así la extracción de sistemas, y el procesamiento por
categorías semánticas, entre otras. Ekbal, Haque y Bandyopadhyay (2008) señalan
que este tipo de etiquetado para los lenguajes naturales “se ha desarrollado
usando reglas lingüísticas, modelos estocásticos y una combinación de éstos.
Los modelos estocásticos 1, 2 y 3 se han usado ampliamente en el etiquetado
sintáctico, siendo el más conocido los Modelos Markov Escondidos (HMMs por sus
siglas en inglés)” (p. 67).
Entre las bondades de WMatrix, al compararlo con otros
softwares similares, está que no se requiere instalar el programa en la
computadora personal, pues se trabaja en línea con los archivos directamente,
independientemente del sistema operativo que se utilice – Mac, Windows, Linux,
Unix. La interfaz es de extrema sencillez, y los datos suministrados, una vez
procesados los textos, son de alta exactitud al remarcar las palabras en
categorías semánticas y gramaticales.
El software contiene
carpetas donde el usuario puede incluir los archivos, formateados previamente
como Archivos de Texto (.txt) con cortes de línea. Una vez subidos los archivos
a sus correspondientes carpetas, creadas por el usuario, se puede iniciar el
proceso de etiquetado gramatical y semántico, paso a paso según lo indica el
propio programa. Se pueden también generar listas de frecuencia, que consisten
en un formato de dos columnas con un número total al comienzo de cada archivo
¿Qué tipos de análisis se pueden realizar
a través de la Lingüística de Corpus?
Existen varios métodos y enfoques en la Lingüística de
Corpus. La forma más básica de procesar información textual es a través de las
líneas de concordancias. Estas permiten sustentar una interpretación textual y
de datos a partir de una impresión intuitiva, respaldada de una forma sencilla,
sin utilizar enfoques más orientados hacia la estadística. También se pueden
obtener tablas de frecuencias de uso de palabras o frases, listas de palabras
que representen temas o imágenes en el texto literario, tablas de colocaciones,
las posibilidades son múltiples, de acuerdo a las preguntas que se formulen en
la investigación.
Para obtener líneas de concordancia, existen programas
informáticos para tal propósito, los cuales buscan palabras o frases seleccionadas
por el investigador, y presentan cada caso que aparezca en el texto, en una
lista donde las palabras o textos se presentan en el centro de la pantalla de
la computadora, con las palabras que le anteceden y le siguen, a la izquierda y
derecha respectivamente. Las líneas lucen como en la siguiente pantalla
(extraída de WMatrix).
Los ejemplos que se presentan a continuación son de la
aplicación de la herramienta WMatrix para el análisis de una novela de la
escritora trinito-baguense Elizabeth Nunez, Bruised Hibiscus (Cayenas
Magulladas), del año 2000, que presenta
inicialmente el descubrimiento, por parte de un humilde pescador, de un cuerpo
femenino mutilado, al parecer de una dama blanca, en el pueblo trinitario de
Otahiti. Aunque luego se duda sobre la etnicidad de la víctima, la sola idea de
que fuese una mujer blanca perturba la tranquilidad de este pequeño
pueblo. El crimen, que los lugareños
califican como “pasional”, renueva la amistad olvidada entre dos personajes
centrales, Rosa DesVignes y Zuela Chin, dos mujeres que viven como seres
despojados de su libertad para expresar quiénes son, qué creencias tienen, sus
valores.
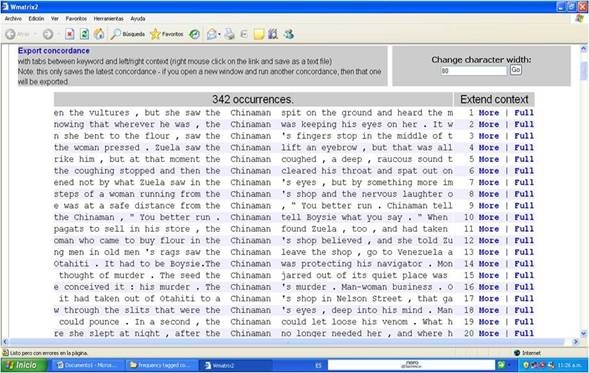
Gráfico 1. Concordancias extraídas de WMatrix para Chinaman. Tomado de: http://ucrel.lancs.ac.uk/wmatrix/ [Consulta: 2011, Julio 4]
La palabra
central es Chinaman (el comerciante chino esposo de Zuela Chin), uno de
los personajes de la novela. En la lista aparecen 342 casos donde esta palabra
es utilizada en toda la novela, con parte del contexto donde se usa. En el caso
de WMatrix, además de cada línea de concordancia, está una columna adicional,
donde se puede solicitar más contexto de cada instancia o línea (More),
o el contexto completo (Full, texto completo). En cualquier caso, los
ejemplos derivados de las concordancias brindan respuestas sólo a través de la
interpretación y la categorización realizada por el investigador, según lo
señala Laura Gavioli (1997, p. 87).
A partir de información como la presentada arriba, se
pueden hacer varias observaciones, según lo señala Susan Hunston (2002, pp.
42-49) en su libro Corpora in Applied Linguistics, y que se enumeran a
continuación:
1. Lo típico y de lo central: lo típico se refiere a los significados o
colocaciones más frecuentes de una palabra o frase, mientras que lo
central tiene que ver con categorías de cosas. Por ejemplo, en castellano el
presente simple generalmente indica acciones habituales, pero en algunos casos
puede hacer referencia a acciones futuras que definitivamente tienen lugar,
como planes pre-establecidos (“Me levanto mañana a las 6 am”). Al examinar los
datos en líneas de concordancias, se puede establecer cuál de estos usos serían
los más frecuentes, de manera que se establezca cuál sería el uso central del
presente simple en castellano.
2. Distinciones en significado: como es bien sabido y señalado en los diccionarios, muchas palabras
tienen significados que se parecen, pero que no pueden sustituirse una por otra
en un texto; en otras palabras, dos palabras sinónimas no siempre pueden
utilizarse en los mismos contextos. La investigación a través de líneas de
concordancias puede brindar información más detallada sobre las distinciones en
significado entre dos o más sinónimos, por ejemplo, en palabras como complet@
y absolut@; en el primer caso, pareciera, según datos a partir de
corpus en inglés, que complete (su equivalente en inglés) se utiliza con
sustantivos que indican ausencia (complete ban, prohibición total),
cambio (complete make-over, transformación completa), y destrucción (complete
collapse, colapso completo). En el segundo caso se utiliza con sustantivos hiperbólicos
(absolute chaos/disgrace/genius, caos/desgracia/genio absoluto). También
se pueden solicitar concordancias sobre los tipos de verbos que reportan el
habla (speech verbs) y examinar los tipos de adverbios que los acompañan, para
detectar patrones actitudinales al reportar lo dicho por los personajes en una
obra literaria determinada.
3. Significados y patrones: aunque la ambigüedad en los significados es posible, los significados de
una palabra o frase pueden distinguirse por los patrones o fraseologías en los
que típicamente ocurren. De manera que una palabra puede tener varios
significados, pero que son discriminables a partir de los patrones de uso donde
típicamente aparece cada uno.
4. Detalle: en el trabajo con concordancias, se puede llegar a observaciones más
específicas sobre el comportamiento de palabras individuales, por ejemplo, qué
palabras generalmente le acompañan, y que connotaciones tiene. En el ejemplo de
concordancias arriba, se trata de uno de los personajes masculinos más cercanos
a una de las protagonistas, Zuela Chin. El nombre de este personaje está
escrito en mayúscula inicial Chinaman, como corresponde a un nombre propio.
Sin embargo, se observa que en la mayoría de los casos, Chinaman está
precedido por el artículo definido the (el), lo cual sustantiviza al
personaje. Es notorio, en un examen más minucioso de los pocos contextos donde Chinaman
NO es antecedido por el artículo definido the, que se trata de la
voz narrativa, en tercera persona, omnisciente, quien hace un tratamiento
adjetivizado de este personaje. Esta sencilla observación sustenta una
intuición interpretativa de los estudiosos de obras literarias postcoloniales
escritas por mujeres del Caribe, según la cual se degrada la figura masculina,
objetivizándolo para acentuar su poca altura humana, su cobardía, y en este
caso particular, el hecho de ser un extranjero residente en Trinidad y Tobago,
venido de China muchos años antes. Para la voz narrativa, se trata de “el
chino”. Cuando los personajes de la novela hablan sobre él o con él,
simplemente dicen “chino”, expresando más cercanía, más familiaridad, un trato
más personal y directo.
Las concordancias
son una herramienta útil para la investigación de corpus, pero su uso se ve
limitado por la habilidad del observador para procesar la información. Existen
otros métodos que involucran cálculos estadísticos de colocaciones y
anotaciones de corpus. A continuación se mencionan algunos de ellos.
Las listas de
frecuencias son listas de todos los ejemplos de palabras en un texto y la
cantidad de veces que se repiten; las mismas se pueden presentar en orden
creciente o decreciente de frecuencia, en orden alfabético, entre otros. Al
comparar listas de frecuencias entre dos o más corpus se puede obtener
información interesante sobre las diferencias entre esos textos, en particular
se ve estos casos en investigaciones sobre textos académicos en los ámbitos EAP
(Inglés con Propósitos Académicos) y ESP (Inglés con Propósitos Específicos).
Las colocaciones
son las tendencias de ciertas palabras a aparecer juntas en un contexto; por
ejemplo la palabra juguetes aparecerá más frecuentemente asociada con la
palabra niños que con las palabras mujeres u hombres. Las
colocaciones se pueden observar más informalmente en cualquier ejemplo de uso
de la lengua, pero se hace más confiable su medición estadística, lo cual es
esencial en cualquier estudio de corpus.
Al estudiar
listas de frecuencias absolutas de aparición de ciertas colocaciones, surge el
problema de la representatividad. En el ejemplo mostrado en el gráfico anterior,
parece obvio que el uso del artículo the antes de la palabra Chinaman
es predominante, por lo tanto significativo estadísticamente. Pero en otros
ejemplos este podría no ser el caso. Entonces, existen medidas estadísticas de
cada co-ocurrencia, tales como el
índice de Información Mutua (MI), que indica la fuerza de una colocación,
la compara con la co-ocurrencia de los dos ítemes con sus co-ocurrencias
esperadas si estas palabras se usaran de forma fortuita en el texto,
completamente al azar. En otras palabras, el índice MI calcula la posibilidad
de la ausencia del azar cuando dos palabras co-ocurren. Matemáticamente, es un
cálculo obtenido dividiendo la frecuencia Observada entre la frecuencia
Esperada, convertida a un logaritmo de base 2, donde cualquier puntaje de 3 o
mayor indica que el resultado es significativo estadísticamente.
Otra medida
estadística es el llamado t-score, que se calcula sustrayendo de la
frecuencia Esperada, la frecuencia Observada, y dividiendo este resultado entre
la desviación estándar. A través del índice MI se conoce la fuerza de una
colocación, pero esto no siempre indica una asociación confiable de su
significado, por lo cual se requiere establecer la certeza de que dicha
colocación sea el resultado de algo más que una simple casualidad en el texto.
Un t-score de 2 o más se considera significativo. De esta manera, se
puede establecer si la asociación de una palabra con otra no es significativa
simplemente por su alta frecuencia en el texto, sino también debido a las
preferencias lexicales de un vocablo determinado. Aquellas colocaciones con un t-score
alto tienden además a proporcionar información acerca del comportamiento
gramatical de una palabra o frase.
En los datos sobre Chinaman procesados a través de
WMatrix, se obtuvieron los siguientes resultados sobre las colocaciones más
típicas o significativas cuyo centro es esta palabra. Los resultados
están en orden decreciente según el índice MI, y en la siguiente columna
aparecen los cálculos según el t-score. Más adelante se discuten
brevemente estos resultados, a manera de ejemplo, sin pretender exhaustividad.
De acuerdo a la
información presentada en la pantalla siguiente, extraída de WMatrix, según el
índice MI parece que la colocación Chinaman’s spy (el espía del chino)
tiene una alta significación en la novela, respecto a este personaje. Sin
embargo el t-score que presenta indica con certeza que se trata más bien
de una peculiaridad del texto, por lo que estadísticamente no parece una
colocación sumamente significativa. Al examinar la colocación the Chinaman
(el chino), presenta un t-score de 5,09 y un índice MI de 3,81 lo cual indica
que es una colocación fuerte y cierta; en otras palabras, es una
colocación significativa en este texto.
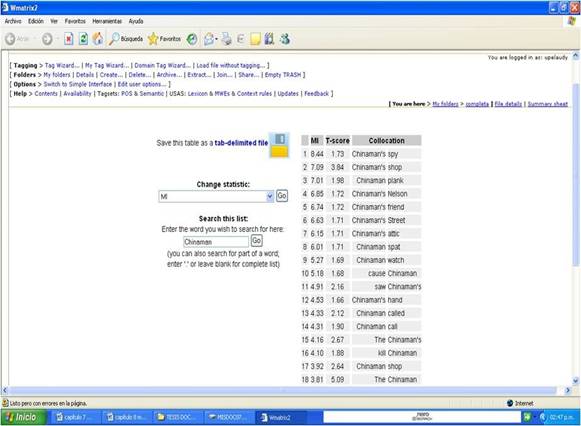
Gráfico 2. Colocaciones extraídas de WMatrix para Chinaman. Tomado de: http://ucrel.lancs.ac.uk/wmatrix/ [Consulta: 2011, Julio 4]
Las implicaciones
a nivel de interpretación apuntan a un sentido actitudinal por parte de la voz
narrativa, quien así establece distanciamiento y hasta cierto desdén por este
personaje. Esta observación se puede complementar
con otras respecto al uso de ciertos vocablos asociados a Chinaman en la
novela, tales como la palabra lizard, que se presenta a continuación.
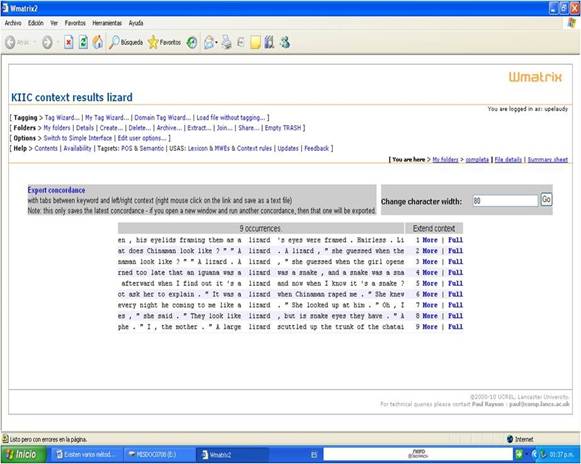
Gráfico 3. Concordancias extraídas
de WMatrix para lizard (iguana). Tomado de: http://ucrel.lancs.ac.uk/wmatrix/ [Consulta: 2011, Julio 4]
En estas nueve
apariciones de la palabra lizard en la novela, siempre está asociada a Chinaman,
pues se comparan sus ojos a los de una iguana, dando una imagen salvaje,
atemorizante. A través de la voz narrativa y uno de los personajes, Zuela, se
compara a Chinaman con una iguana, por sus movimientos (“he coming to me
like a lizard”, “él acercándose a mí como una iguana”) y por su mirada (“his
eyelids framing them as a lizard (…) Hairless”, “sus párpados moviéndose como
los de una iguana (…) Sin pestañas”). Se describe a Chinaman en forma
fragmentada, comparándolo con un reptil, para acentuar su influencia negativa
en la vida de Zuela Chin.
Las
interpretaciones derivadas de información proporcionada por paquetes como
WMatrix tienen como punto de partida las intuiciones de quien investiga,
sustentadas o confrontadas por evidencia cuantificable. Las concordancias y
demás tipos de información exigen prestar atención a los rasgos lingüísticos
del texto y examinar qué hay en el lenguaje que genera las intuiciones e impresiones provenientes de una lectura
superficial de un texto.
Estas medidas
estadísticas pueden sustentar la información que se obtiene a través de las
concordancias; permite además manejar grandes cantidades de datos. Sin embargo,
advierten los expertos, entre ellos Susan Hunston (2002, p. 79), se debe ser
cauteloso en la interpretación de los datos; los cálculos de colocaciones
siempre darán prioridad a los usos de una palabra que tienden a ser
restringidos o fijos desde la perspectiva léxica, mientras que otros usos
pueden parecer menos significativos cuando se examinan listas de
colocaciones. Es importante entonces reconocer
la importancia de colocaciones altamente significativas pero sin interpretarlas
erróneamente.
Los resultados
arrojados por paquetes informáticos, como WMatrix, no hablan por sí mismos,
según advierte Howard Jackson (1997). Los resultados “tienen que ser
interpretados y evaluados; las conclusiones, derivadas y relacionadas con las
preguntas iniciales de la investigación” (p. 236).
Jackson propone
una serie de recomendaciones para el proceso de investigación lingüística a
través de corpus y paquetes informáticos que analizan textos. A nivel de los objetivos,
el autor recomienda justificar la escogencia del texto, así como definir las
preguntas que serán respondidas a través del corpus seleccionado. En cuanto al método,
que se explique cómo se utilizó el software para explorar el texto y llevar a
cabo la investigación. Al reportar los resultados, que se tomen en
cuenta los temas más relevantes para la interpretación, que se comenten los
resultados en función a su relevancia y relación con los objetivos del estudio.
Finalmente, en una etapa evaluativa, que se reflexione sobre el proyecto
ejecutado, se comente sobre las ventajas y limitaciones de los análisis de
textos asistidos por la computadora.
Jackson también
señala que la investigación de corpus, realizada según los parámetros
mencionados en el párrafo anterior, se caracterizan por revelar lo
inesperado (el “serendipity factor”, ob cit., p. 238).
Louw (1997) por
su parte, señala que los datos obtenidos a partir de corpus analizados a través
de paquetes como WMatrix, pueden apoyar la intuición de quien lee. En el caso
de textos literarios, señala que las “concordancias y/o colocaciones pueden
tener significado simbólico, ya que los autores pueden hacer que los símbolos
aparezcan sin ninguna relación con sus colocaciones habituales” (p. 248). Para
llegar a conclusiones válidas, hay que “examinar los significados expresados en
las colocaciones” (p. 250).
Elementos gramaticales para determinar
la connotación de
las palabras en un texto
En el análisis textual que
se realiza desde el ámbito gramatical, se hace necesario examinar el valor o
connotación de cada palabra, especialmente sustantivos, adjetivos y adverbios.
Esta afirmación tiene como sustento varias hipótesis que se asumen en esta
investigación respecto al contenido ideológico de los textos literarios. En
primer lugar, existe una gran variedad de textos, en múltiples géneros y modos
de presentación, que representan de una manera explícita o, mucho más
comúnmente, de una manera implícita, una visión de mundo, una ideología,
opiniones, sentimientos, valores. Debido a esto ha aumentado recientemente la
demanda de herramientas que permitan clasificar los textos no solamente según
el tema que abordan, sino especialmente en cuanto a las actitudes y opiniones
manifiestas en ellos; así, surgen nuevas áreas dentro del Procesamiento de
Lenguaje Natural, identificadas como el Análisis del Sentimiento e
Identificación de la Matriz de Opinión (Opinion Mining and Sentiment Analysis,
OMSA, por sus siglas en inglés).
Sin entrar en detalles sobre las investigaciones
que se realizan en esta área, en la literatura más reciente se reconoce que
ciertas palabras en un texto pueden modificar a otras, ya sea intensificando,
disminuyendo o cambiando completamente su sentido. Por ejemplo, en la oración
“él no es inteligente”, el valor positivo de inteligente es modificado a
negativo por la palabra no antes del verbo. Existen varios tipos de
palabras que ejercen esta influencia sobre otras en el texto, y es en éstas que
se han de prestar atención a efectos del análisis textual que se ha emprendido
de la novela de Elizabeth Nunez Bruised Hibiscus.
1.
Palabras
negativas, intensificadoras, y reductoras: el efecto de palabras como no,
nunca, ninguno, muy, algo, un poco,
entre otras, es que pueden negar una connotación intensificadora, intensificar
una connotación negativa.
2.
Conectores:
algunas conjunciones como pero, mientras que, aunque, sin
embargo, introducen un contraste deliberado en la discusión al introducir
información nueva y contradiciéndola inmediatamente. La cláusula principal de
la oración es la que expresa la actitud de quien emite el mensaje, y así el
efecto de la misma se neutraliza por el uso del conector. Son formas
explícitas, aunque sutiles de manifestar un punto de vista.
3.
Verbos: aunque
las oraciones de un texto estén formadas por vocablos con connotaciones
negativas, por ejemplo, el uso de ciertos verbos pueden cambiar estos
significados, logrando así un efecto positivo en el mensaje. Algunos verbos que
hacen posible estos cambios son: atacar, detener, prohibir, prevenir, rechazar,
entre otros.
Estos
señalamientos ponen en evidencia la necesidad de examinar el lenguaje en
contexto, tomando en consideración no sólo los elementos en forma individual,
sino en su co-texto, vale decir, en su interrelación con las demás palabras del
texto.
Otra información que
puede examinarse en WMatrix tiene que ver con la clasificación general de
campos semánticos para la novela completa. Esta
lista de clasificación semántica presenta en orden clave los ítemes más
resaltantes que aparecen en el texto de la novela. A partir de este cuadro
pueden hacerse observaciones generales. Por ejemplo, parece razonable que los
pronombres predominen como categoría, puesto que este tipo de palabras crean
coherencia textual y léxica, al evitar la repetición innecesaria de los nombres
propios o las frases que describen a cada personaje. Llama la atención que sea
el grupo anatomía y fisiología el que aparezca en primer lugar; sin
embargo, ha de destacarse que los personajes femeninos, especialmente Rosa
DeVignes, son presentados a través de las partes de su cuerpo, sus reacciones
fisiológicas frente al abuso verbal por parte de Cedric, al llorar, por
ejemplo. También hay un énfasis en una descripción de personajes como Chinaman
a través de una parte de su cuerpo (los ojos de iguana, los ojos negros).
Luego
sigue en la lista los conceptos negativos, donde se incluyen palabras que
disminuyen el valor de otras, tales como little/pequeño, tiny/enano, diminuto,
pain/dolor, murderer/asesino, poison/veneno, rage/rabia,
frightened/atemorizado(a); son palabras que dan un sentido pesimista,
oscuro, al relato.
Seguidamente están los
grupos humanos, empezando con las mujeres. Esto parece lógico, dado que es una
novela escrita por una mujer caribeña, sobre dos mujeres que viven en Trinidad.
La quinta categoría, knowledgeable/que tiene conocimientos, forma
parte de la clasificación general de acciones psicológicas, procesos y estados.
Esto es importante, porque Bruised Hibiscus es una novela con personajes
que actúan poco, que permanecen estáticos frente a los acontecimientos, que
piensan, sienten, dicen, preguntan, ejecutan acciones mentales verbalizadas o
no, pero que en realidad no emprenden acciones más contundentes.
El gráfico
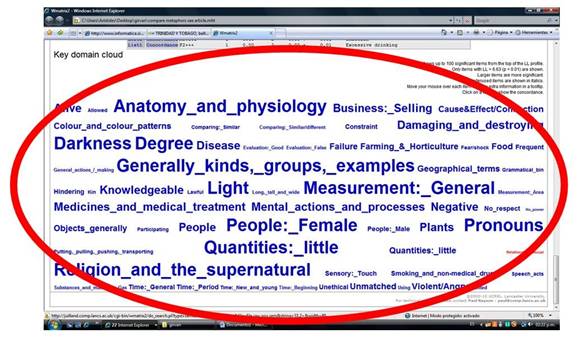
Gráfico 4.
Dominios semánticos mostrados por grupos de categorías, donde a mayor tamaño
mayor significación estadística, según WMatrix
CONCLUSIONES
Algunas
narrativas de la región caribeña se resisten a ser encasilladas en términos
absolutos y se proponen como espacio de intersección entre la épica y la
tragedia, la Historia nacional y la historia individual, el poder y la
resistencia. Son maneras, desde mundos ficticios construidos en los espacios
literarios, de re-escribir la historia, re-interpretar el pasado colonial, y
superar los efectos de la hegemonía por tantos siglos. Bruised
Hibiscus ha sido el texto de referencia para ejemplificar, con la
asistencia de WMatrix, algunos elementos ideológicos presentes en el imaginario
caribeño, tal y como lo conciben autoras como Elizabeth Nunez.
La gran fragmentación
que existe en el Caribe, por la nombrada violencia epistémica a la que
Gayatri Spivak hace referencia, se manifiesta en el mundo ficticio donde los
personajes de Bruised Hibiscus interactúan. Hay divisiones debido a la
raza: personas blancas que desprecian a los negros, pero que tienen sexo e
hijos con ellos; personas de color que se avergüenzan del color de su piel,
mientras que al mismo tiempo sienten un odio y resentimiento viscerales por la
gente blanca, al punto de llegar al asesinato con tal de dar una lección a la gente
blanca, como es el caso de las agresiones en Laventille, santuario de la Virgen
de Fátima; gente amarilla, asiática, que no se mezclan con los negros ni los
blancos, sino que prefieren a los marrones, gente de color de otras latitudes,
como Suramérica. Hay divisiones debido al lenguaje: la familia de Cedric, de
origen humilde, hablan en dialecto, una lengua informal, con trazas de antiguas
lenguas africanas, arahuacas, taínas, mezcladas con el inglés y en ocasiones
con el francés. Cedric se asimila culturalmente a Gran Bretaña a través de su
educación, refugiándose en los libros para lograr un hablar refinado y culto,
que esconde tras de sí un profundo desprecio por su grupo étnico y en esencia
por sí mismo.
¿Qué
hay de los asiáticos? En el mundo creado por Elizabeth Nunez son seres
aislados, no establecen alianzas a menos que se trate de acuerdos comerciales.
Del mismo modo, aprenden a comunicarse en inglés estrictamente por razones
laborales. En el fondo, como sucede con Ho Sang y Tong Lee, traen consigo
recuerdos muy dolorosos, que los persiguen día y noche, hasta originarles
pesadillas o incluso la adicción a las drogas como medio para evadir los
penosos recuerdos.
¿Hay
acaso en este mundo ficticio posibilidades de integración? Las diferencias son
múltiples, los enigmas, las vergüenzas, las historias dolorosas. Pero hay
esperanza: se trata de ver en el otro a sí mismo, en empatía, con
amor, solidaridad, comprensión, tolerancia, en fin, en vías hacia la paz.
No
es la pertenencia a un grupo étnico el resultado de haber nacido con cierto
color de piel. En Venezuela hay ejemplos de sobra de personas que lucen como
europeas, en contextura y color de piel, pero que descienden de africanos,
chinos, indios, aborígenes. La mezcla interracial hace prácticamente imposible
identificarse en una etnia determinada tan solo por la apariencia física.
La
pertenencia a un grupo étnico más bien viene dada por los referentes
socio-culturales: en las costumbres, la gastronomía, los hábitos del día a día,
las creencias, los valores. En el mundo ficticio de Bruised Hibiscus,
estos elementos surgen una y otra vez. La herencia cultural de cada personaje,
rica en posibilidades, choca repetidamente con la dinámica social de Trinidad,
donde hay inquietud, inconformidad, donde se cometen crímenes atroces sin que
las autoridades, tan burocráticas como ineficientes, hagan algo al respecto. La
única recomendación a las damas blancas es la de “no acercarse a Laventille sin
sus criadas y guardaespaldas”, a riesgo de ser atacadas por bandas de jóvenes
negros resentidos.
Subsisten los prejuicios, pero al fin y
al cabo surgen sentimientos positivos, el amor y la admiración. Tong Lee
siempre “admiró la belleza” de Zuela y “también admiraba su alma (…) su
espíritu floreció a pesar del desierto que el Chinaman había creado para ella.”
Tong Lee cierra un ciclo floral que las cayenas magulladas abrieron para
presentar un mundo convulsionado, en constante cambio; él siembra unos arbustos
de cayena roja en una esquina del jardín de su casa, ahora también de Zuela y
sus hijos. Estas cayenas fueron el homenaje fúnebre apropiado para Rosa, pues
después de todo, había sido un arbusto de cayenas las que las había separado en
su infancia, y otro arbusto de cayenas las que las había reunido después de veinte
años.
Se presentó en este artículo el resultado
del tratamiento del texto de la novela Bruised Hibiscus mediado por
computadora, en la forma de un software creado por Paul Ryson conocido como
WMatrix. Diversos conceptos relacionados con la hegemonía y el subalterno debieron operacionalizarse a través de redes
y campos léxico-semánticos, que con WMatrix pudieron ser sistemáticamente
develados, clasificados y presentados según su significación estadística,
siempre sobre la base de la intuición de quien conduce el análisis, enmarcada
en los planteamientos teóricos, metodológicos, literarios, históricos,
geo-históricos, culturales, sociales, socio-lingüísticos, entre otros, que
ofrecieran una visión suficientemente amplia y exhaustiva de los conceptos que
se intentaron explorar.
Por
supuesto que el uso de WMatrix no implicó en modo alguno que la herramienta
abrumara con la gran cantidad de datos a la intérprete de los mismos; tampoco
determinó ni sesgó en modo alguno el análisis realizado. La herramienta permitió
el manejo de grandes cantidades de datos en un breve tiempo, pero con un margen
de exactitud que superaba el 90%, un pequeño margen de error de 10% atribuible
a ambigüedades léxicas no resueltas por el software, o debido a transcripciones
erróneas de algunas palabras, o palabras nativas, propias del léxico
trinitario, que no forman parte del diccionario que nutre a WMatrix, y por lo
tanto, pasaron etiquetadas como “Grammar bin” (basura gramatical) o por
categorías no definidas.
En este sentido, se complementó la
información proporcionada por WMatrix con la lectura “cerrada” del texto; una
lectura muy cuidadosa de la novela, a partir de la cual resaltaran algunas
palabras, citas, narraciones, pasajes, descripciones que fueran de relevancia
para develar diversos aspectos a partir de la interpretación por parte del
lector.
BIBLIOGRAFÍA
Baker, P. (2006). Using
Corpora in Discourse Analysis. Londres: Continuum.
Bradford, R. (1997). Stylistics.
Londres: Routledge.
Ekbal, A., Haque, R., y Bandyopadhyay, S. (2008).
Maximum Entropy Based Bengali Part of Speech Tagging.
En A. Gelbukh (Comp.), Advances in
Natural Language Processing and Applications Research in Computing Science 33:
pp. 67-78.
Gavioli, L. (1997).
Exploring texts through the Concordancer: Guiding the learner. En A. Wichmann,
S. Fligelstone, T. McEnery y G. Knowles (Comps.), Teaching and Language
Corpora, pp. 83-99. Londres: Adisson-Wesley Longman.
Halliday, M.A.K. y
Matthiessen, C.M.I.M (2004) An Introduction to Functional Grammar 3rd
Edition.
Hoare, Q. and Smith, N.G.
Eds. (1971) Selections from the prison notebooks of Antonio Gramsci.
Hoey, M. (2005) Lexical
Priming: A new theory of words and language. Oxon: Routledge.
Hoey, M. (2006) Language
as choice: what is chosen?, in S. Hunston and G. Thompson (eds) System and
corpus: exploring connections, pp. 37-54.
Holden, P. (2002) The
Subaltern: Political Discourse – Theories of Colonialism and Postcolonialism.
Singapore:
National University of Singapore [Documento en línea] Disponible: http://www.usp.nus.edu.sg/post/poldiscourse/subaltern.html
[Consulta: 2011, Julio 6]
Hunston, S. (2002). Corpora
in Applied Linguistics.
Jackson, H. (1997).
Corpus and Concordance: finding out about Style. En A. Wichmann, S.
Fligelstone, T. McEnery y G. Knowles (Comps.), Teaching and Language Corpora,
pp. 224-239. Londres: Adisson-Wesley Longman.
Loomba, A. (1998) Colonialism/Postcolonialism.
Louw, B. (1997). The role
of Corpora in critical literary appreciation. En A. Wichmann, S. Fligelstone,
T. McEnery y G. Knowles (Comps.), Teaching and Language Corpora, pp.
240-252. Londres: Adisson-Wesley Longman.
McLeod, J. (2000) Beginning
Postcolonialism.
Morse, J. (1994).
Emerging from the data: the cognitive processes of analysis in qualitative
inquirí. En J. Morse (Comp.), Critical Issues in Qualitative Research
Methods, pp. 23-43.
Murfin, R. y Ray, S.
(2003). The
Nunez, E. (2000). Bruised
Hibiscus.
Ransome, P. (1992) Antonio
Gramsci: A New Introduction.
Rivkin, J. y Ryan, M.
(2004). Literary Theory: an anthology.
Short, M. (1996). Exploring
the language of poems, plays and Prose. Londres: Longman.
Weber, J. (1996). The
Stylistics Reader: From Roman Jakobson to the Present.. Londres:
Wynne, M. (2005).
Stylistics: corpus approaches, en K. Browm (comp.), The Encyclopaedia of
Linguistics.
|