



El proyecto de Enriquecimiento de Datos y Métodos de Análisis (EDMA) tiene como objetivo enriquecer, aprovechar y explotar los datos producidos por la Infraestructura Ontológica de la Información del SUE (IOI-SUE) y la Arquitectura Semántica de Datos del SUE (ASD-SUE). Tanto la IOI-SUE como la ASD-SUE facilitan el manejo y publicación de datos semánticos; ambos proyectos están profundamente relacionados.
Este subproyecto se enfoca en usar dichos datos y asegurar la sostenibilidad de la infraestructura de la manera siguiente:
- El lote 1, Enriquecimiento de Datos, está destinado a facilitar su enriquecimiento mediante el uso de fuentes de información disponibles en Internet y que son de uso habitual por parte de la comunidad investigadora. Además, se espera que desarrollen mecanismos para que los investigadores participen activamente en la validación y actualización de su información. Gestionar la información enriquecida mediante el concepto de Research Object3 (RO), de forma que se facilite a los investigadores la gestión de sus RO, sin que esto signifique generar una infraestructura específica para cada tipo de RO.
- El lote 2, Métodos de Análisis, tiene por objetivo permitir la explotación y la analítica de datos con propósitos de inclusión y participación a varios niveles de los agentes implicados. Por ejemplo, ciencia ciudadana, diseminación para no expertos, aplicaciones que faciliten la conformación de redes de expertos y proyectos, aplicaciones que permitan buscar e identificar expertos, aplicaciones que permitan a las universidades y a la sociedad en general conocer la capacidad investigadora en tópicos específicos, tanto a nivel de recursos humanos como de producción científico-técnica
Además, mediante las APIs de conexión que se desarrollarán, se generará comunicación entre los componentes de software relacionados con el Sistema de Gestión de la Investigación y demás funcionalidades pertenecientes al proyecto Hércules. Por lo tanto, serán una interfaz que permita comunicar las aplicaciones de Gestión de la Investigación de la Universidad con las bases de datos disponibles.
El enriquecimiento se refiere a la capacidad de HERCULES para hacer uso de datos que sean servidos por aplicaciones externas a HERCULES. Este enriquecimiento será completamente configurable y orientado, idealmente, a consumir los datos de la(s) API(s) que se consideren útiles para agregar valor a la nube de datos HERCULES.
Servicios centrales (HERCULES Core Services)
Este módulo proveerá de una serie de servicios que se describen a continuación, y que serán relevantes para otros módulos a desarrollar en el Lote 1 y en el Lote 2.
Módulo Single Sign-On (SSO)
HERCULES deberá proveer métodos programáticos que permitan a los usuarios registrados acceder a múltiples aplicaciones de HERCULES con un único usuario y clave. Este módulo no debe confundirse el Single Login Entry Point, descrito a continuación.
Módulo Single Login Entry Point (SLEP)
HERCULES deberá facilitar al usuario un registro único a través del cual sea posible acceder a múltiples aplicaciones web usando únicamente el sistema de identificación de HERCULES.
Por ejemplo, un usuario HERCULES se autentica. A través de la interfaz web el usuario procede a autorizar a la plataforma HERCULES a acceder a su GitHub , FigShare , SlideShare , LinkedIn , SHARE , etc. Esta autorización será guardada y manejada por HERCULES de manera en que el usuario no tenga que llevar a cabo este proceso de autenticación y autorización cada vez que entre a HERCULES. En los casos en los cuales las aplicaciones tengan restricciones de seguridad que dependen del tipo de dato, esto deberá también ser gestionado a través de la interfaz de HERCULES.
HERCULES creará así un registro de identidades para el usuario. De esta manera, HERCULES sabrá que el usuario X es YYYY en ORCID y KKKK en GitHub. Además, HERCULES tendrá las autorizaciones correspondientes para que las aplicaciones que usen el sistema HERCULES SSO hereden esta capacidad para gestionar múltiples identidades y así acceder a múltiples aplicaciones.
La facilidad de estar en capacidad de autenticar y autorizar a HERCULES en múltiples plataformas deberá ser extensible. El adjudicatario deberá iniciar con GitHub, FigShare, LinkedIn, SlideShare, data.world , Dataverse , ORCID y SHARE, además de con los servicios de autenticación de las universidades nacionales miembros de CRUE. Deberá además asegurar la extensibilidad de este componente con el propósito de agregar más aplicaciones en la medida en que sea necesario.
Módulo de administración de usuarios
Se deberá desarrollar para HERCULES un módulo que permita crear, editar, borrar y suspender usuarios. Este módulo deberá también definir los roles y permisos para los diferentes tipos de usuarios HERCULES. La definición de los perfiles de usuario deberá ser coordinada con el módulo SSO. Este módulo también gestionará la seguridad asociada a cada perfil de usuario.
Gestión de FAIR Research Objects (HERCULES FAIR RO)
Módulo de Gestión de RO
Los investigadores tienen sus Objetos de Investigación (en adelante abreviado como Research Objects, RO) en varios repositorios, por ejemplo, FigShare, SlideShare, Git, SHARE, SGI HERCULES, etc. Esto implica que a la diversidad de RO habrá que añadirle la complejidad propia de manejar dichos RO sobre varias aplicaciones. Debido a la especialidad de cada aplicación para manejar ciertos tipos específicos de RO, por ejemplo, GitHub para código, esta situación no cambiará. Por lo tanto, se requiere que HERCULES permita, idealmente, al investigador declarar y catalogar sus RO independientemente de la aplicación en la que se encuentren. Con el propósito de manejar la situación antes descrita HERCULES facilitará al investigador, vía APIs y métodos OAUTH disponibles, el “reclamar” (del inglés claim) sus RO de cada aplicación.
Una vez que el usuario haya reclamado sus RO, HERCULES los registrará a su nombre guardando todos los metadatos asociados y además estableciendo la trazabilidad de la proveniencia. Más aún, se deberá investigar y desarrollar un modelo de metadatos que permita al usuario describir el RO cumpliendo los principios FAIR. El manejo de los RO implica también establecer relaciones entre RO que provengan de diferentes aplicaciones. Es así como, por ejemplo, el usuario debería poder establecer la relación entre un preprint en Share con un dataset en FigShare y con un código en GitHub. De esta manera el RO resultante será una agregación de los RO individuales. Se espera que la composición y enriquecimiento del RO suceda en una interfaz gráfica que permita manipulación directa de los RO. Ejemplos de este tipo de funcionalidad se pueden ver en https://rmap-hub.org.
Este módulo deberá también sugerir al investigador la inclusión de RO de aquellos sitios autorizados que no hayan sido incluidos y que estén relacionados con el investigador. De esta manera, si un investigador autoriza a HERCULES sobre FigShare, “reclama” en FigShare solo un RO y omite reclamar los demás RO a su nombre, entonces recibirá sugerencias que le indicarán que tiene pendientes de reclamar otros RO a su nombre en FigShare.
De manera similar se espera que este módulo también construya sugerencias de RO pertenecientes a otros investigadores HERCULES que hayan llevado a cabo el proceso de autorización. Este módulo, una vez autorizado, tendrá conocimiento de los RO a nombre del investigador en la aplicación autorizada. Esto le permitirá a HERCULES perfilar dichos RO asignándoles tópicos de investigación. Por ejemplo, para un poster en FigShare, este módulo podrá extraer los tópicos del poster y determinar así a qué usuario HERCULES podría serle de interés. Una vez hecho este cálculo, procederá a llevar a cabo la correspondiente sugerencia. Un proceso similar se espera para perfilar el RO sobre los demás sitios contra los que se lleve a cabo la autorización; por ejemplo, un repositorio en GitHub puede ser perfilado y tópicos de investigación asignados a este perfil, por ejemplo, Python como lenguaje de programación. La recomendación puede entonces ser para un usuario HERCULES que también sea un programador en Python.
Toda la extracción automática de tópicos, y los tópicos asociados a un RO, deberán también estar disponibles vía una API. Esta API deberá facilitar el consumir estos datos con el propósito de, por ejemplo, agregar los tópicos.
A continuación, de forma no exhaustiva, se listan algunos de los posibles repositorios que se podrían tener en consideración para este fin:
- WikiData
- Dbpedia
- OpenAire
- Crossref
- Share
- VIVO
- Elsevier
- Eprints
- WebOfScience
- Zenodo
- Springer Nature SciGraph2
- Linked Open Data Eurostat3
- H2020 API4
Módulo de gestión integrada de Research Objects
Los RO son agregaciones de varios RO así como también son los elementos principales de dicha agregación. Es así como se puede tener un RO de un solo elemento. Existen RO de muy diferentes tipos y el manejo de cada tipo específico de RO en cuanto a registro, enriquecimiento (manual y automático), exportación, importación, establecimiento de relaciones automáticas, etc. no es del todo genérico. Existen matices propios de cada RO.
Se describen en los próximos apartados algunos tipos específicos de RO sobre los cuales HERCULES, vista como plataforma de Open Science, tiene interés: código, referencias bibliográficas, anotaciones manuales y protocolos experimentales. Se esperan propuestas innovadoras para el manejo integrado de un variado abanico de RO. Es importante resaltar que un RO puede tener valor por sí mismo; la agregación añade valor al conjunto y además crea valor para aquellos que hayan participado en su definición y su creación.
Módulo de código
Un tipo específico de RO es el código y todo su proceso asociado, por ejemplo, versionado, documentación, tests unitarios, etc. Este RO tiene una complejidad propia del código. Se espera que los proponentes aporten soluciones prácticas que permitan extraer y anotar repositorios de GitHub y BitBucket . Una vez registrado el repositorio a nombre del investigador HERCULES relacionado con dicho repositorio se espera que el módulo pueda desambiguar, o permitir que el usuario lo haga, el tipo de relación que se tiene con el repositorio. Por ejemplo, ¿es un repositorio que creó de novo el investigador o es un fork de otro repositorio? Si es un clon de otro repositorio, ¿existe trabajo propio del investigador que diferencie el repositorio del original?
El código generado por un investigador es parte de sus assets, y como tal debe ser posible cuantificarlo dentro del conjunto de su producción académica. Este módulo deberá permitir dicha cuantificación, contribución, trabajo original, derivado, etc. en relación al código en repositorios de sistemas tipo Git. Se pretende darle valor al código generado por un investigador; de igual manera se debe investigar y desarrollar un modelo de metadatos que permitan la descripción de dicho código y cuantificar el código como parte de la producción académica de un investigador. Documentación, ejemplos de uso, metadatos sugeridos por el autor, tópicos automáticos asignados por HERCULES a dicho código, son solo algunos aspectos que deberán permitir caracterizar y cuantificar dicho RO.
Módulo de referencias bibliográficas
Las referencias bibliográficas son un conjunto de anotaciones puntuales sobre el texto que se dereferencian contra un documento externo. Vistas como RO, su representación se estima la más sencilla, y a partir de las mismas se pueden establecer varios tipos de relaciones con el texto dependiendo del tipo de citación. Por ejemplo, una URL, un documento publicado o una comunicación personal. El módulo de referencias bibliográficas deberá resolver las referencias en los papers publicados por investigadores HERCULES, capturar los metadatos, enriquecer con tópicos los metadatos de las publicaciones referenciadas y armar para el investigador un mapa conceptual donde pueda apreciarse su trayectoria investigativa, que cita, relación entre los tópicos de sus papers y aquellos que cita. Se espera que este módulo haga extenso uso de recursos tales como Open Citation , Citeseerx , CrossRef, European PMC , etc.
Módulo de anotaciones manuales
Existen varios tipos de anotaciones, dependiendo del propósito. Por ejemplo:
- Con el propósito de generar una referencia entre un elemento específico dentro del paper o documento a un archivo externo al documento, por ejemplo, una figura o código.
- Con el propósito de ampliar o explicar un elemento narrativo dentro del texto; no se tiene la expectativa de generar una discusión sobre este tipo de anotación. Se refiere a anotaciones hechas por los autores a manera de post-publicación. Por ejemplo, aquellas relativas a literatura más reciente relacionada con una parte del texto.
- Con el propósito de generar una discusión sobre un elemento narrativo dentro del documento se espera que sobre esta anotación otros puedan participar. Este tipo de anotaciones pueden, por ejemplo, referirse a partes del texto que generen controversia. Pueden también ser aquellas anotaciones en las cuales cualquier lector cuestiona una parte especifica dentro del texto.
Se esperan propuestas que permitan la anotación de un documento, y que cubran los casos presentados anteriormente. Se espera además que las anotaciones sean tratadas como RO; por lo tanto deberán seguir los estándares correspondientes, por ejemplo, aquellos propios de un RO y además aquellos propuestos por el Open Annotation Framework . Todo el sistema de anotación deberá contar con su API, sistema de exportación e ingestión de documentos, deberá estar coordinado con el anotador automático (identificador de tópicos) descrito en el presente pliego, y se espera que los proponentes reutilicen sistemas ya existentes tipo Dokieli o Hypothes.is.
Módulo de Registro de Protocolos de Experimentales
Los protocolos experimentales describen el flujo de trabajo a llevar a cabo cuando se realiza un experimento. Estos flujos son de muy diversos tipos; siendo los más conocidos aquellos relativos a life sciences, experimental protocols. Los protocolos experimentales no son usados únicamente en el dominio bio y en medicina. Todas las áreas de trabajo tienen protocolos de algún tipo. Este módulo no pretende estandarizar la manera de reportar flujos de trabajo en investigación. En cambio, pretende simplemente hacer de cualquier tipo de protocolo experimental un RO de primer orden FAIR.
Para lograr esto es necesario que se estandaricen los metadatos para protocolos experimentales en ciertos dominios. ¿Qué tienen en común, cual es el mínimo común denominador? Y con estos metadatos se registran como Ros, permitiendo luego el manejo de un RO en HERCULES; esto es, el establecimiento de relaciones con otros RO. Por ejemplo, el modelo Sample, Instrument, Reagent, Objective (SIRO: Giraldo 2017, Giraldo 2018) cubre una gran variedad de protocolos en el dominio biológico. De la misma manera existen otros estándares de mínima información que pueden ser usados para soportar el registro de otro tipo de protocolos experimentales. Se espera que se determine cómo registrar una gran variedad de protocolos experimentales para así FAIRificarlos y además tener explícita la relación entre el protocolo experimental y los resultados además de las publicaciones relacionadas.
Este repositorio deberá ser sencillo de usar, facilitar acceso a los datos vía API, y además estar debidamente documentado. Se espera también que esté comunicado con el módulo de extracción de tópicos y toda la maquinaria para gestión de RO.
Módulo de valorización de RO
Los RO representan aquellos productos de investigación que se crean, manejan, distribuyen, comparten y modifican en el curso de una investigación. Como tal, los RO son parte de los resultados u outcomes de una investigación. El valor de los RO está concentrado en el documento publicado; sin embargo, este valor no refleja la cadena de producción establecida en una investigación. Tampoco refleja contribuciones ni el valor creado en la investigación. Para efectos prácticos se pierde el valor de todo RO que no sea una publicación. Esta inequidad genera una pérdida en valor para el sistema de investigación; es un activo sobre el cual no se establece ningún valor y por lo tanto se desecha. Esto va en detrimento directo del interés del investigador en ser reconocido por sus productos y además del sistema de investigación por no ser capaz de contabilizar este tipo de valores.
Se buscan aquí soluciones innovadoras que permitan establecer un valor para todos los ROs producidos en una investigación. Se espera poder tener un registro que considere la generalidad del RO pero que también sea capaz de reconocer aquellos matices específicos de ciertos RO, por ejemplo, protocolos de investigación, protocolos clínicos, código, etc. Se espera que las propuestas en este sentido permitan también generar una moneda de agregación que permita para cada RO en posesión de un investigador, el poder desagregar y determinar así la procedencia de dicho RO. Por ejemplo, en qué investigación fue producido, cómo ha sido reusado, quien lo ha reusado, modificaciones, etc. Para este escenario sería de interés valorar soluciones innovadoras basada en Blockchain o en sistemas tipo Interplanetary File System (IPFS) .
Procesamiento y análisis de Research Objects (HERCULES RO Enrichment)
Módulo de extracción de tópicos
Los investigadores registrados en HERCULES tienen una gran variedad de publicaciones. Estas son descritas con metadatos que cada revista provee. Sin embargo, esta descripción es indirecta por cuanto no se deriva directamente del contenido. Con el propósito de mejorar los tópicos de experiencia derivados de las publicaciones de un investigador, este módulo extraerá dichos tópicos directamente de las publicaciones. Una vez extraídos estos harán parte de los tópicos que describen la experiencia del investigador. Cada tópico extraído de esta manera deberá tener sus propios metadatos, entre otros indicando la proveniencia (por ejemplo, DOI de la publicación de la cual fue extraído, y método de extracción aplicado).
La extracción automática de tópicos de investigación no es exacta. En vista de lo anterior en todos los casos el investigador deberá estar en capacidad de corregir el tópico de experiencia sugerido por el algoritmo. Deberá tenerse trazabilidad para estas correcciones y el algoritmo aprenderá con la experiencia. De manera similar se espera que sobre el HERCULES Dashboard (se describirá más adelante) se implemente una funcionalidad que permita a otros investigadores HERCULES sugerir tópicos de experiencia para sus colegas. Un ejemplo del tipo genérico de flujo de trabajo esperado se da a continuación:
- El usuario configura el servicio con el que quiere enriquecer los datos. Idealmente, el usuario podría tener un listado de API configurado por defecto, con la finalidad de seleccionar solamente aquel con el que realizará el enriquecimiento.
- El sistema automáticamente presenta al usuario aquellos conceptos o propiedades con las que se puede hacer un match entre el knowledge graph y el API que configuró en el paso anterior. Adicionalmente, el usuario tendrá la opción de seleccionar aquellos conceptos o propiedades que le interese enriquecer. Estos resultados estarán ordenados según la similitud que tengan con el recurso original.
- Una vez que el proceso se ejecuta se visualizan los resultados en la pantalla. El usuario decide si aceptar o no el enriquecimiento de entre todas las propuestas disponibles y ejecuta el enriquecimiento.
HERCULES permitirá ejecutar las tareas más habituales de Procesamiento de Lenguaje Natural con la finalidad de realizar la extracción de los tópicos de investigación a partir de publicaciones y ROs. Para ello el adjudicatario tendrá que implementar/reutilizar herramientas que permitan el análisis completo del texto de las publicaciones o de los ROs basado en la extracción automática de términos. Es de especial interés para HERCULES la reutilización de desarrollos financiados por el Plan de Impulso de las Tecnologías del Lenguaje del Gobierno de España, así como estar alineados con iniciativas internacionales relacionadas con la European Open Science Cloud.
El adjudicatario presentará una propuesta de cómo abordará este módulo de acuerdo con los criterios y herramientas que considere necesarias para su implementación. Como punto de partida, el adjudicatario tendrá en cuenta que la mayoría de métodos para la extracción automática de términos realizan un procesamiento en dos fases: procesamiento lingüístico y procesamiento estadístico, por lo tanto, tendrá que especificar cómo abordará dichas fases. Para el procesamiento lingüístico, tendrá que especificar qué método empleará para, por ejemplo, etiquetar partes de frases, filtrar las palabras usadas como stop words, etc. Para el procesamiento estadístico, tendrá que especificar qué método de extracción automática de términos empleará y la justificación de su elección, por ejemplo, C-value/NC-value (Frantzi 1999). Un aspecto importante que también tendrá que considerar el adjudicatario es que el módulo soportará la extracción de términos en inglés y en español.
Módulo de similitud semántica
La similitud semántica textual tiene como objetivo determinar cuándo el sentido de dos textos es similar. Este concepto difiere de encontrar el grado de similitud textual, relativo a medir el número de componentes léxicas que comparten ambos textos. En el contexto de HERCULES se espera que los proponentes presenten una solución que permita al usuario final ver similitud semántica entre textos.
Es así como por ejemplo se espera que, para una publicación, HERCULES indique aquellas publicaciones que son similares en el contenido, comunicando al usuario de manera clara cómo y por qué los documentos encontrados por HERCULES son similares a uno dado por el usuario, es decir, explicar las similitudes.
De la misma manera se espera que este módulo de HERCULES sea capaz de obtener la similitud entre RO. Por ejemplo, si el usuario tiene un RO de tipo código, Python 3.1, con datos de entrada de tipo secuencias genómicas, y además términos como GWAS (Genome-Wide Association Studies) y Oryza Sativa están en la descripción de este RO entonces se espera que dentro de los RO conocidos por HERCULES se encuentren aquellos que son similares y se le sugieran al usuario como RO similares.
Perfil del investigador (HERCULES Researcher Dashboard)
Módulo Researcher Dashboard
HERCULES permitirá que el usuario sea capaz de administrar los datos de su perfil. Por lo tanto, este módulo permitirá al usuario autorizar al conjunto de aplicaciones HERCULES en otras aplicaciones para indicar dónde está y cuál es su producción científico-técnica. Por ejemplo, usando APIs y OAUTH el usuario deberá poder autorizar a HERCULES para listar aquellos ítems a su nombre en FigShare. Este enriquecimiento de su perfil a partir de datos en la web deberá generar un registro sobre las bases de datos HERCULES. Una vez capturada la producción del usuario sobre diferentes aplicaciones web, se enriquecerán estos objetos con descripciones provenientes de los vocabularios controlados usados por HERCULES. Además, el usuario deberá contar con visualizaciones que le permitan entender de forma gráfica su trayectoria; estas visualizaciones serán construidas contra los datos suministrados y también contra aquellos capturados de plataformas terceras. Este módulo también recuperará la información de un investigador en cualquier nodo de la red HERCULES.
Este módulo debe tener en cuenta la funcionalidad desarrollada para la gestión del CV del investigador en el pliego SGI HERCULES (expediente E-CON-2019-53), compartiendo los aspectos de modelado e interfaz que aseguren el desarrollo óptimo y la interoperabilidad de ambos. Este módulo tendrá como fuente importante de información los datos procedentes del SGI HERCULES publicados semánticamente, pero podrá mostrar información recuperada de otras fuentes que no esté disponible, o compartida por el SGI HERCULES. Las actualizaciones de información que realice el investigador usando HERCULES Researcher Dashboard serán notificadas al SGI de la institución del investigador. Este módulo también notificará a la institución del investigador la nueva información disponible, procedente de otras fuentes, no ofrecida por el SGI HERCULES. Este módulo ofrecerá la vista de edición complementaria al Portal Web de Investigación incluido en el pliego SGI HERCULES, por lo que los adjudicatarios deberán colaborar para obtener un resultado integrado a la par que optimizado para sus tipos de usuarios.
El usuario que interactuará directamente con el módulo incluido en este pliego será el Investigador. Entre las necesidades que este módulo satisfará se tienen:
- Ingresar/editar los datos de mi currículum, el modelo deberá seguir al menos la estructura del CVN de FECYT. De ser posible, HERCULES deberá poder cargar vía API los datos directamente de fuentes externas y del SGI HERCULES. Permitirá comunicar los datos al SGI HERCULES, para la actualización del CV del investigador en su institución. Los ítems de datos esperados incluyen, pero no están limitados a:
- Datos personales (nombre, apellidos, NIF/NIE, correo electrónico, etc.)
- Datos de identificación de investigador (ORCID, Google Scholar, etc.)
- Formación académica (grado, máster, doctorado, etc.) en la que se indiquen los detalles del título obtenido, la fecha, el centro de formación, etc.
- Formación complementaria, por ejemplo, en idiomas extranjeros. Para cada formación se incluirá la fecha, el nombre del certificado obtenido, etc.
- Área/disciplina de conocimiento.
- Trayectoria laboral en la que se indique la fecha de inicio/fin, descripción de actividades realizadas, nombre del cargo, modalidad, entidad empleadora, etc.
- Proyectos en los que haya participado incluyendo los roles que he desempeñado.
- Producción científica que haya generado, por ejemplo, artículos, software, datasets, etc. Para cada resultado científico se incluirá el título, fecha de publicación, DOI, referencia asociada, etc.
- Patentes, diseños industriales, etc. que haya registrado ya sea como titular o como cotitular.
- Premios recibidos en los que se recoja el nombre y el año de obtención. Por ejemplo, alguno de los Premios Nacionales de Investigación.
- Participación en eventos de divulgación científica, por ejemplo, congresos, talleres, noche de la ciencia, etc. Incluyendo mi rol de participación.
- etc
- Obtener el listado de los trabajos que he dirigido/codirigido ya sean de grado (TFG), máster (TFM), o tesis doctorales.
- Obtener el listado de congresos/workshops y eventos de divulgación científica en los que haya participado indicando el rol que he tenido: organizador, expositor, etc.
- Obtener el listado de patentes, diseños industriales, etc. que haya registrado como titular o cotitular X o Y persona, Z o K institución.
- Obtener el listado de proyectos en los que he participado incluyendo el rol que he desempeñado, por ejemplo, investigador principal.
- Obtener el listado de mi producción científica.
- Obtener el listado de startup o spin-off que he fundado o de las que he sido socio.
- Obtener los indicadores de mi producción científica como, por ejemplo, total de citas, h-index, etc.
- Visualizar mi trayectoria según la línea del tiempo y parametrizable de acuerdo criterios como, por ejemplo, proyectos, tesis dirigidas/codirigidas, etc.
- Saber si soy apto para solicitar una evaluación relativa al nuevo sexenio de transferencia del conocimiento e innovación1 o alguna de las evaluaciones que realiza la ANECA .
- Introducir ofertas tecnológicas dirigidas a empresas, para lo cual tendré que describir la oferta, asociarle un nivel de madurez (TRL) y asociar evidencias que soporten el nivel de madurez asignado.
Este lote incluye una serie de aplicaciones que permitirán la explotación y el análisis de los datos existentes en HERCULES.
Búsqueda de investigadores -Módulo Research Synergy Finder
HERCULES permitirá que un usuario realice búsquedas de investigadores y su producción científica con la finalidad de facilitar la detección de posibles nichos de colaboración y alianzas estratégicas. Una práctica frecuente en investigación es aquella relativa a conformar grupos de trabajo con el propósito de armar consorcios que participan en aplicaciones para dinero que apoya la investigación. Este tipo de asociaciones se llevan a cabo en muchos casos de manera subjetiva; los investigadores se asocian con aquellos que conocen, no necesariamente con los más indicados para conformar un grupo con el propósito de abordar un problema o aplicar para una subvención. HERCULES deberá facilitar a los usuarios detectar sinergias, encontrando investigadores que cumplan determinadas características con el propósito de, por ejemplo, ser más competitivos cuando se aplica a una ayuda. Los casos de uso a resolver por parte de este módulo incluyen recomendar potenciales socios para formar un consorcio con la finalidad de participar en la licitación de un proyecto, identificar expertos
que sean capaces de evaluar propuestas de proyectos, etc. En cualquier caso, este módulo será capaz de presentar una interfaz en la que el usuario pueda filtrar, por áreas/disciplinas de conocimiento, aquellos centros/estructuras de investigación de las universidades españolas en las que se estén desarrollando actividades de investigación en un área/disciplina de interés.
Entre las funcionalidades que como mínimo se espera sean cubiertas en este módulo se listan las siguientes:
- Como usuario requiero obtener un listado de los centros/estructuras de investigación que trabajan en un área/disciplina específica.
- Como usuario requiero obtener un listado de los investigadores de un centro/estructura de investigación de un área/disciplina específica. Este listado podrá filtrarse según el tipo de investigador ya sea docente, personal investigador en formación, etc.
- Como usuario requiero obtener el Top 10 (o el número que se considere relevante pues será parametrizable) de los investigadores de un centro/estructura de investigación ordenados por el número de citas, número de publicaciones, h-index, etc. en un área/disciplina específica.
- Como usuario requiero obtener el Top 10 (o el número que se considere relevante pues será parametrizable) de centros/estructuras de investigación que posean sellos de calidad asociados, por ejemplo: el sello Severo Ochoa.
- Como usuario requiero obtener un listado de los centros/estructuras de investigación que hayan realizado proyectos H2020 y/o proyectos del Plan Estatal.
- Como usuario requiero obtener un listado de la producción científica en un determinado rango de fechas de un centro/estructura de investigación en un área/disciplina. Para cada resultado se incluirán algunos metadatos importantes de la producción como, por ejemplo, DOI, año de publicación, etc.
- Como usuario requiero obtener una visualización en la que se recoja la distribución de la producción científica española, por ejemplo, de artículos publicados en revistas, según las comunidades autónomas en un rango de años.
- Como usuario requiero comparar comunidades autónomas, universidades, grupos de investigación, etc. en determinados tópicos para identificar cuál es el más competitivo y por qué.
- Como usuario requiero obtener un listado de patentes, diseños industriales, etc. de un centro/estructura de investigación en un área/disciplina.
- Como investigador y personal no investigador de la universidad requiero obtener un listado de los proyectos adjudicados/desarrollados, de un centro/estructura de investigación, de un área/disciplina, en un determinado año de búsqueda en los que se tenga acceso al detalle de al menos:
- Nombre del proyecto
- Palabras claves
- Tipo de participación: coordinador o participante
- Tipo de proyecto: competitivo o no competitivo
- Tipo de financiamiento: público o privado.
- Tipo de convocatoria: nacional, H2020, etc.
- Número y listado de personas involucradas en el proyecto
- Nombre(s) del investigador(s) principal
- Entregables/memoria del proyecto
- Producción científica relacionada con el proyecto
- Entidades colaboradoras/participantes
- Cuantía
- etc.
- Como usuario académico no investigador necesito conocer el tamaño, experiencia y envejecimiento de un área de investigación a escala de universidad, regional, nacional.
- Como usuario necesito conocer el porcentaje de participación de un centro/estructura de investigación en proyectos nacionales o europeos.
Desde el punto de vista de detección de sinergias, se desea responder a la necesidad de obtener la recomendación de un clúster de colaboración conformado por investigadores relacionados según la similitud entre artículos científicos de un área/disciplina de interés. El número de investigadores que conforman el clúster será parametrizable. En caso de que exista una carencia de investigadores para el área disciplina de interés, el módulo será capaz de sugerir investigadores de un área similar para poder al menos contar con aquellos profesionales que estén relacionados con la temática de interés.
Este módulo permitirá que el usuario indique el (las) área/disciplina(s) de interés y el número de expertos (N) que necesita encontrar. Tras esta configuración básica, el usuario tendrá la opción de configurar los criterios adicionales para la selección. De forma no exhaustiva se mencionan a continuación algunos criterios relevantes que el adjudicatario tendrá en cuenta para la valoración de cada investigador:
- Número de proyectos nacionales, europeos, etc. en los que ha participado y su rol.
- Número de citas, h-index, etc.
- Número de patentes.
- Etc.
Adicionalmente, este módulo permitirá la configuración del peso de cada uno de estos criterios con respecto a la valoración total, por ejemplo, número de citas 25%, número de proyectos europeos en los que ha participado 50%, rol de participación como investigador principal en proyectos europeos 25%, etc.
En el caso de que no existan investigadores en el área/disciplina de interés requerido se hará uso de las características de inferencia de las ontologías desarrolladas en Hércules ASIO para sugerir aquellos investigadores del área más similar. Esta recomendación vendrá acompañada del detalle del área/disciplina a la que pertenece el investigador recomendado incluyendo el detalle del área/disciplina(s) que se ha tenido que recorrer dentro del grafo hasta llegar al resultado (haciendo referencia al ejemplo de ontologías del apartado Web Semántica de este documento, si Microbiología Clínica es una subárea de Microbiología y estamos buscando en nuestro sistema un experto en Microbiología Clínica y no disponemos de ninguno, el sistema podría recomendar un experto en Microbiología antes que uno en Genética, ya que son áreas más cercanas semánticamente. Por lo tanto, el detalle del camino que se añadiría al investigador recomendado sería Microbiología Clínica - Microbiología). Así también, se presentará la posición del investigador de entre los N investigadores recomendados según la calificación obtenida. Se espera que el adjudicatario proponga más criterios para realizar las recomendaciones (que podrán ser extraídos incluso del módulo de indicadores) y las fórmulas para calcular las calificaciones de cada investigador.
Cuando haya finalizado la recomendación, el usuario tendrá acceso automático al CV completo de los investigadores sugeridos por la plataforma.
Análisis de proyectos de investigación - Módulo de Gestión y Análisis de Proyectos
HERCULES permitirá que el usuario sea capaz de analizar los resultados de los proyectos de investigación que se están llevando a cabo en un centro/estructura de investigación. Por lo tanto, el objetivo de este módulo es incrementar la transparencia y facilitar las labores de gestión y seguimiento de los proyectos que el usuario coordine o en los que participe un centro/estructura de investigación. La fuente primaria de información será la procedente del SGI HERCULES que haya sido compartida en formato semántico. El SGI HERCULES deberá poder acceder a los servicios de análisis a nivel de red HERCULES generados por este módulo.
Este módulo cubrirá al menos el siguiente listado de necesidades:
- Como investigador, personal no investigador de la universidad requiero insertar/modificar los datos relacionados con los proyectos de investigación, incluyendo los entregables que se hayan generado en la fase de propuesta. El usuario tendrá acceso a esta información según el nivel de acceso que se le haya proporcionado previamente según su rol, según niveles de confidencialidad de ser el caso. Entre los datos que se proporcionarán por cada proyecto se tendrá al menos:
- Nombre del proyecto
- Palabras claves
- Tipo de participación de la entidad: coordinador o participante
- Tipo de proyecto: competitivo o no competitivo
- Tipo de financiamiento: público o privado
- Tipo de convocatoria: nacional, H2020, etc.
- Número y listado de personas involucradas en el proyecto
- Nombre(s) del investigador(s) principal
- Entregables/memoria del proyecto
- Producción científica relacionada con el proyecto
- Entidades colaboradoras/participantes
- Cuantía
- Etc.
- Como usuario necesito una visualización que me permita explorar la información de cada proyecto según los filtros que haya elegido, por ejemplo, por años, por tipo de convocatoria, por cuantía mayor a determinado valor, según un área/disciplina, según la ubicación geográfica, etc.
- Identificar proyectos con temática y objetivos científicos similares. En este caso, el usuario podrá acceder a visualizaciones comparativas de la información de proyectos similares.
- Como usuario necesito una visualización que me permita analizar la evolución de un investigador, conjunto de investigadores o líneas de investigación a través de los resultados de los proyectos realizados. Se podrá hacer una selección de los proyectos a incluir. El usuario podrá acceder a visualizaciones comparativas de la información de investigadores, conjuntos de investigadores o líneas de investigación seleccionados.
Análisis de indicadores de investigación - Módulo de Catálogo de indicadores.
Se proveerá al usuario de indicadores de investigación e innovación que le permitan medir la investigación nacional a partir de la información disponible en la red HERCULES y en fuentes externas. Como mínimo este módulo será capaz de calcular los valores de al menos 20 indicadores (este número es una aproximación pues podrían considerarse más o menos indicadores) que tendrán que ser propuestos por el adjudicatario para que sean validados por la entidad contratante. Se tendrán en cuenta para ellos los indicadores que se definan como fundamentales en el pliego SGI HERCULES (expediente E-CON-2019-53). Se deberá poder incorporar cualquier indicador creado según el modelo a desarrollar en el pliego SGI HERCULES.
Como punto de partida el adjudicatario se podrá referir a los indicadores usados a nivel nacional (por ejemplo, por el INE ) y a nivel internacional (por ejemplo, u-ranking ) que se consideren relevantes (según diferentes áreas por ejemplo enseñanza, investigación, citas, transferencia tecnológica, etc.). Algunos indicadores que también pueden servir de referencia son aquellos mencionados por el Plan Estatal de Investigación Científica y Técnica y de Innovación 2017-2020 :
- Número de publicaciones científicas en colaboración internacional.
- Porcentaje de publicaciones científicas en colaboración internacional.
- Porcentaje de inversión total en I+D ejecutado por organismos de investigación de la Administración Pública y por instituciones de enseñanza superior.
- etc.
Otros ejemplos de indicadores son aquellos descritos en el informe European Innovation Score Board , por ejemplo:
- Gasto en R&D en el sector público (expresado en porcentaje del Producto Interno Bruto)
- Publicaciones científicas, de entre el top 10 de las más citadas a nivel mundial, expresadas como el porcentaje del total de las publicaciones científicas del país.
- etc.
El adjudicatario tendrá que mencionar, en el caso de aquellos indicadores que requieran datos externos, cuáles son y cómo se obtendrán para realizar el cálculo. Algunas fuentes de datos externas son el INE , Eurostat , Web of Science , para calcular, por ejemplo, el valor del Producto Interno Bruto en España, el número de habitantes, etc.
Son de interés también indicadores de colaboración público-privada y de financiación privada de la actividad de investigación y transferencia.
Este módulo será capaz de cubrir al menos las siguientes necesidades:
- Como usuario necesito obtener el listado de indicadores con su respectivo valor y unidad de medida (porcentaje, número, etc.) calculados en un periodo de tiempo, ya sea para toda la universidad o para cada centro/estructura de investigación de cada universidad.
- Como usuario necesito una visualización de la evolución de indicadores según la línea del tiempo (años, trimestres, etc.)
- Como usuario necesito acceder a una predicción de la evolución de indicadores a partir de la serie temporal de sus valores y de las variables existentes en el sistema que se consideren relacionadas, lo cual se podrá parametrizar.
- Como usuario necesito detectar tendencias en áreas y líneas investigación a partir de los datos disponibles en Hércules.
- Como usuario necesito cuantificar la contribución de cada investigador, línea de investigación, área de conocimiento, centro de investigación, comunidad autónoma, etc. a cada indicador.
- Como usuario tengo interés en hacer clusters de líneas y áreas de investigación, investigadores, grupos, centros de investigación, comunidades autónomas, etc. usando como criterio de clasificación uno o varios indicadores de productividad a elegir por el usuario,
- Como usuario investigador y gestor, estoy interesado en conocer qué líneas y áreas de investigación, investigadores, grupos, centros de investigación, comunidades autónomas, etc. presentan desviaciones significativas con respecto a la media de los indicadores de productividad científica.
- Como decisor tengo interés en conocer el perfil y evolución de la relación de investigación y transferencia de una empresa con un conjunto de centros de investigación en un período de tiempo.
La contratación precomercial se desarrollará en distintas fases eliminatorias de forma que se vaya comprobando progresivamente la eficacia y eficiencia de las soluciones propuestas por cada uno de los contratistas que compiten entre sí para crear soluciones innovadoras que den mejor respuesta los Requisitos Funcionales señalados en el Pliego.
LOTE I

LOTE II
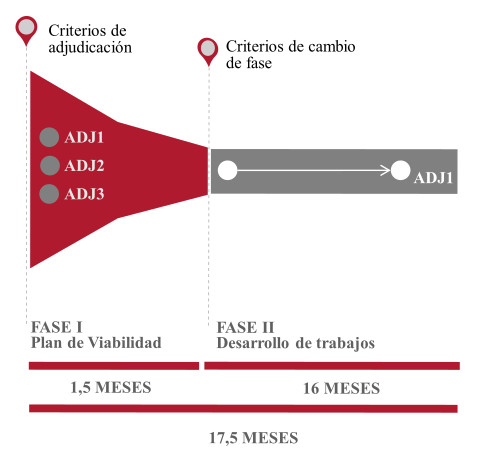
FASE I, ESTUDIO DE LA VIABILIDAD DE LA SOLUCIÓN PROPUESTA
ESTADO: finalizado.
Durante esta fase, encaminada a asegurar el mayor grado de adecuación de las soluciones propuestas científico-tecnológicas y el plan de I+D al reto planteado, los contratistas realizarán un estudio de viabilidad con el que observaron el funcionamiento y necesidades del servicio destinatario de la solución recopilando todos los datos necesarios a fin de demostrar la viabilidad técnica y económica del proyecto propuesto en relación con el objetivo y la necesidad planteada.
Al término de esta fase presentaron una versión final adaptada de la documentación justificativa de la solución propuesta que será sometida a un proceso de evaluación.
Para esta evaluación se utilizaron los criterios de evaluación y selección establecidos en esta Fase 1 y podían ser seleccionados, para el acceso a la Fase II, un único contratista por cada lote de entre los que obtubiesen la mejor puntuación siempre que sus soluciones obtuvieran la puntuación mínima requerida.
FASE II, DESARROLLO DE LA SOLUCIÓN.
ESTADO: no iniciada
Esta fase está enfocada a obtener, por parte de los contratistas seleccionados, un desarrollo de la solución que permita evaluar la capacidad de la solución propuesta para cumplir e incluso superar los Requisitos Funcionales señalados en el pliego, realizando - en su caso- todos los ajustes necesarios, las pruebas y estudios adicionales que sean necesarios para completarlo.
PRESUPUESTO LOTE 1. ENRIQUIMIENTO DE DATOS
| Concepto | Presupuesto sin IVA | IVA | Total |
|---|---|---|---|
| Fase1 | 44.628,10 € | 9.371,90 € | 54.000,00 € |
| Fase 2 | 393.388,43 € | 82.611,57 € | 476.000,00 € |
| Total | 438.016,53 € | 91.983,47 € | 530.000,00 € |
PRESUPUESTO LOTE 2. MÉTODOS DE ANÁLISIS
Precio sin IVA |
IVA |
Total |
|
|---|---|---|---|
Fase1 |
29.752,07 € |
6.247,93 € |
36.000,00 € |
Fase 2 |
284.297,52 € |
59.702,48 € |
344.000,00 € |
Total |
314.049,59 € |
65.950,41 € |
380.000,00 € |
DOCUMENTOS Y ENLACES
- Expediente de contratación (Expediente 2019/72/OT-AM)
- Anuncio de licitación
- Publicación en DOUE
- Memoria justificativa
- Documento de aprobación del expediente
- Pliego
- Resolución nombramiento Comité Técnico de Evaluación
- Jornada CRUE Preguntas y Respuestas
- Resolución rectificación error material PCPP
- Acta de calificacion documental
- Acta apertura Sobre A y Memoria Científico-Técnica Sobre B
- Acta apertura Sobre C. Criterios evaluables de forma automática
PROTOCOLO NORMAS DE PUBLICIDAD HERCULES
ED

EDMA LOTE 1: ENRIQUECIMIENTO DE DATOS
Hito 1. Marzo 21
- Modelos de metadatos para la descripción y anotación de FAIR RO (Research Objetct) 70%
Hito 2. Junio 21
- Modelos de metadatos para la descripción y anotación de FAIR RO 85%
- Librería de Extracción de tópicos 40%
- Librería de enriquecimiento de FAIR Research Objects 30%
Hito 3. Octubre 21
- Modelos de metadatos para la descripción y anotación de FAIR RO 100%
- Librería de Extracción de tópicos 100%
- Librería de enriquecimiento de FAIR Research Objects 100%
- Librería Similitud semántica 60%
Hito 4. Enero 22
- Librería Similitud semántica 100%
- Resultados de la ejecución del plan de pruebas 100%
Hito 5. Septiembre 22 (Fin de proyecto)
- Plataforma implementada
- Imágenes Docker de cada módulo
- Manuales
- Resultados de la ejecución del plan de pruebas
- Código fuente
- Materiales formación
MA

EDMA LOTE 2: MÉTODOS DE ANÁLISIS
Hito 1. Marzo 21
- Análisis y diseño 80%. Diseño completado de la interfaz de usuario y modelo de navegación.
- Modelo digital 70%. Diseño del modelo de indicadores (1ª versión).
- Resultados de la ejecución del plan de pruebas del modelo digital. Pruebas ejecutadas sobre la versión del modelo de indicadores
Hito 2. Junio 21
- Análisis y diseño 90%.
- Modelo digital 85%. Diseño del modelo de indicadores (2ª versión)
- Modulo Research Synergy Finder. Primer ciclo de desarrollo realizado (50%).
- Primera versión de la librería de métodos de análisis, visualización y predicción
- Primera versión de la librería de detección de sinergias
- Primera versión del módulo proyectos. Primer ciclo de desarrollo realizado (50%)
Hito 3 Octubre 21
- Análisis y diseño
- Modelo digital. Diseño del modelo de indicadores finalizado
- Modulo Research Synergy Finder + Proyectos
- Segunda versión de la librería de métodos de análisis, visualización y predicción
- Segunda versión de la librería de detección de sinergias
- Segunda versión del módulo proyectos. Segundo ciclo de desarrollo realizado (90%)
- Primera versión del desarrollo del modelo de indicadores (50%)
Hito 4. Enero 22
- Modulo de proyectos finalizado - conexión con el Sistema de Gestión de la Investigación (SGI)
- Desarrollo del modelo de indicadores finalizado
Hito 5. Septiembre 22 (Fin de proyecto)
- Plataforma implementada. Desarrollo de todos los módulos finalizado.
- Arquitectura de despliegue en la nube (Docker)
- Librerías de sistemas finalizadas (métodos de análisis, visualización, predicción y sinergias)
- Documentación y manuales
- Resultados de la ejecución del plan de pruebas
- Entrega del repositorio de código fuente
- Material de formación
En lo relativo al lote I, la U.T.E. RIAM INTELEARNING LAB, S.L. - UNIVERSIDAD DE DEUSTO se han validado los primero entregables de la fase II del proyecto
En cuanto al lote II, la empresa RIAM INTELEARNING LAB, S.L se han validado los primero entregables de la fase II del proyecto
Se puede acceder a la documentación a través del siguiente enlace. La documentación está estructurada en el árbol de navegación de la izquierda.
| Lotes | Herramienta de CV | Portal Nacional Avanzado de Investigación |
| Documentación | Análisis funcional Enriquecimiento de Datos - Hércules - Confluence (um.es) |
Análisis funcional de Métodos de análisis - Hércules - Confluence (um.es) |




