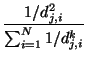
|
Los diferentes métodos de interpolación desarrollados pueden dividirse en dos tipos fundamentales:
Los métodos globales asumen la dependencia de la variable a interpolar de otras variables de apoyo. Pueden darse dos situaciones en función del tipo de variable de apoyo que se utilice:
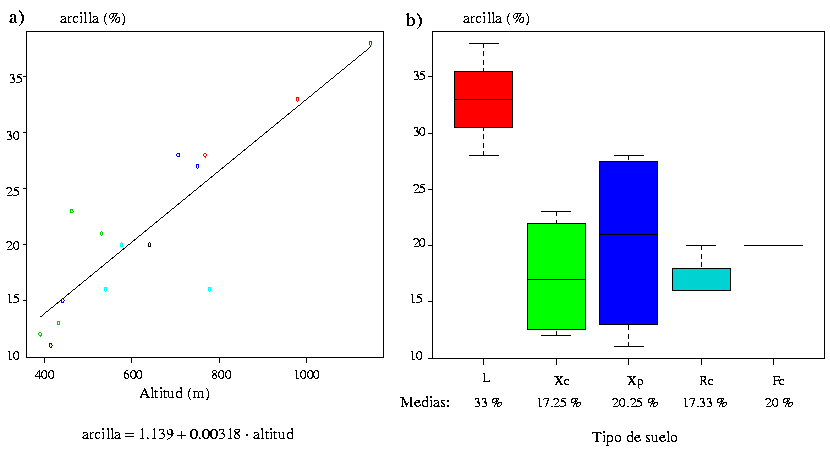
La variable de apoyo es cualitativa (usos del suelo, tipos de suelo o roca, etc). En este caso se asume que la variable adopta en cada punto el valor medio correspondiente al valor de la variable de apoyo en ese punto. Por ejemplo si se trata de interpolar el contenido en arcilla de los suelos, puede utilizarse el tipo de suelo como variable de apoyo y asignar a cada suelo su contenido medio de arcilla (figura 53). Estos métodos se basan en una serie de premisas que no se cumplen necesariamente:
El resultado es equivalente a una reclasificación que produce un mapa en el que los diferentes valores de V se transforman en valores de Z
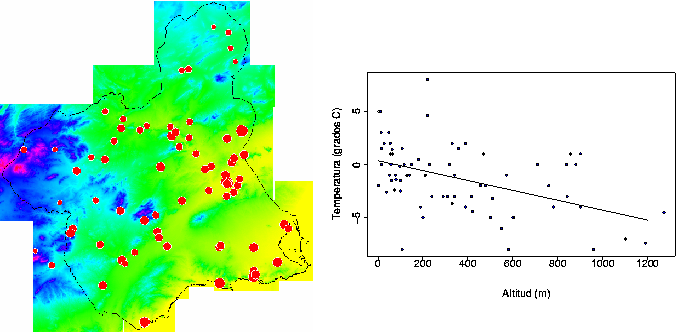
Implican, como su nombre indica, un análisis de regresión previo a partir del cual se genera un modelo de interpolación de tipo polinómico. Generalmente se utilizan X e Y (longitud y latitud) como variables de apoyo ya que no necesitan de ninguna medición, y también alguna variable cuantitativa V espacialmente distribuida, un ejemplo habitual es la altitud, y otras variables topográficas derivadas, por su facilidad de medida, su evidente relación con casi todos los procesos ambientales y por las posibilidades que un SIG ofrece en cuanto al tratamiento de la elevación e información derivada. No resulta recomendable utilizar polonómios de grado mayor que 3 ya que, a pesar de un ajuste cada vez mejor, se hacen cada vez más sensibles a los valores extremos con lo que cualquier error en los datos podría generar distorsiones importantes en el resultado final.
En ambos casos (clasificación y regresión) se requiere una análisis estadístico previo para determinar que los datos se ajustan al modelo estadístico implicado. En el caso de la clasificación que las medias de las diferentes clases son significativamente diferentes y que las desviaciones típicas dentro de las clases son pequeñas (figura 53). En el caso de la regresión es necesario verificar que el coeficiente de correlación es significativamente elevado (figura 54).
El problema de los métodos globales es que sólo consiguen modelizar una componente a escala global de la estructura de variación, pero no las componentes a escala más detallada, por tanto se utilizan para filtrar esa componente global y eliminarla de los valores medidos para, posteriormente, estimar tan sólo la componente local mediante métodos locales.
Los métodos locales se basan en la utilización de los puntos más cercanos al punto de interpolación para estimar la variable Z en este, llamaremos al conjunto de puntos más cercanos conjunto de interpolación. Asumen autocorrelación espacial y estiman los valores de Z como una media ponderada de los valores de un conjunto de puntos de muestreo cercanos. Exigen tomar una serie de decisiones:
El semivariograma nos permite determinar un valor de distancia de forma objetiva, lógicamente el valor umbral no debe superar el valor del alcance de este..
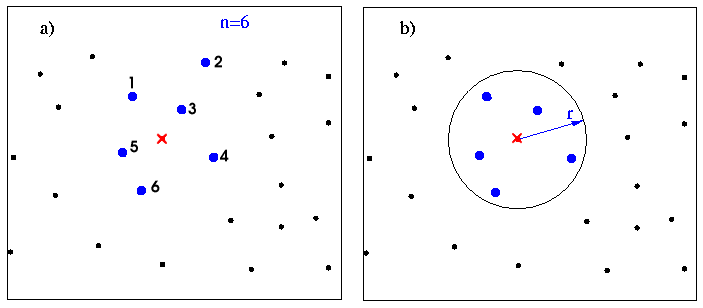
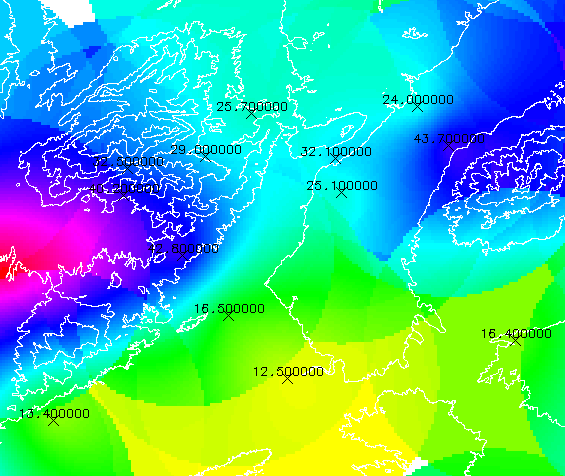
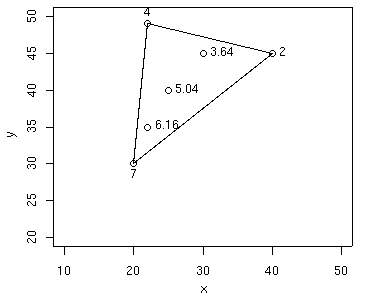
Por ejemplo, suponiendo que los valores de distancia (di) al punto de interpolación (representado por una x en la figura 55) y de precipitación (Zi) medidos en los puntos del conjunto de interpolación seleccionado en la figura 55.a son los que aparecen en la tabla 2
| i | di | Zi |
| 1 | 52.7 | 33 |
| 2 | 90.9 | 27 |
| 3 | 33.8 | 45 |
| 4 | 56.3 | 44 |
| 5 | 36.4 | 46 |
| 6 | 54.8 | 41 |
La estimación de Z en el punto de interpolación sería:
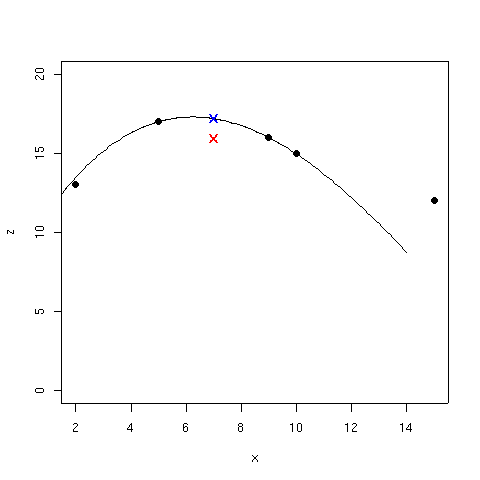
Uno de los problemas más importantes de los métodos basados en medias ponderadas es que, como su propio nombre indica, interpolan basándose en el valor medio de un conjunto de puntos situados en las proximidades, por tanto nunca se van a obtener valores mayores o menores que los de los puntos utilizados para hacer la interpolación. En consecuencia no se van a interpolar correctamente máximos o mínimos locales y además los puntos de muestreo aparecen en el mapa final como máximos y mínimos locales erroneos. En la figura 58 se muestra un ejemplo en una sola dimensión tratando de interpolar el valor de Z en el punto de coordenada X = 7, como puede verse el método de media ponderada por inverso de la distancia genera un valor poco razonable entorno a 15 (la X roja) dada la tendencias observada en los puntos.
El método de los splines ajusta funciones polinómicas en las que las variables independientes son X e Y. Es similar a una interpolación global mediante regresión, pero ahora esta interpolación se lleva a cabo localmente. En general producen resultados muy buenos con la ventaja de poder modificar una serie de parámetros en función del tipo de distribución espacial de la variable.
La técnica de splines consiste en el ajuste local de ecuaciones polinómicas en las que las variables independientes son X e Y. La forma de la superficie final va a depender de un parámetro de tensión que hace que el comportamiento de la superficie interpolada tienda a asemejarse a una membrana más o menos tensa o aflojada qure pasa por los puntos de observación.
La ventaja fundamental del método de splines respecto a los basados en medias ponderadas es que, con estos últimos, los valores interpolados nunca pueden ser ni mayores ni menores que los valores de los puntos utilizados para interpolar. Por tanto resulta imposible interpolar correctamente máximos y mínimos. En la figura 58 podemos ver como el método de splines genera en este caso una estimación mucho mejor, el valor de la curva a su paso por X=7, al menos visualmente, que da un valor en torno a 18.
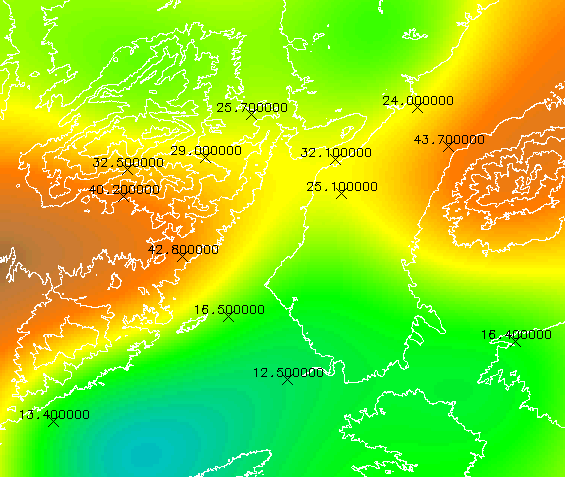
Las Redes Irregulares de Triángulos (TIN son las iniciales en inglés) se generan a partir de valores puntuales tratando de conseguir triángulos que maximicen la relación área/perímetro, el conjunto de todos los triángulos forma un objeto geométrico denominado conjunto convexo. Suelen utilizarse como método para representar modelos de elevaciones (y producen resultados visualmente muy buenos) sin embargo a la hora de integrarlos con el resto de la información raster es necesario interpolar una capa raster a partir de los triángulos (figuras 61 y 62).
Esta interpolación se basa en que cada uno de los tres vértices de los triángulos tienen unos valores X, Y y Z a partir de los cuales puede obtenerse un modelo de regresión Z = AX + BY + C que permite interpolar la variable Z en cualquier punto del rectángulo. En definitiva puede asimilarse a un método de media ponderada por inverso de la distancia ya que el resultado siempre va estar acotado por los valores máximo y mínimo de Z en los vértices del triángulo y será más parecido al del vértice más cercano. En el resultado final de una interpolación TIN no aparecen artefactos circulares, como en los de inverso de la distancia puros, pero si aparecen artefactos triangulares.
En el ejemplo de la figura 55 el punto de interpolación estaría en el triángulo formado por los puntos 3,4 y 5, lo que significa que sus coeficientes de ponderación serían (aplicando la ecuación 35 con k = 1): W3 = 0.395, W4 = 0.237, W5 = 0.367 Z = 45.1.
El conjunto convexo así generado tiene otra utilidad, define el área en la que es razonable interpolar dada la muestra de puntos disponible.