Caso práctico resuelto
Introducción
En este caso práctico vamos a estudiar la existencia de relaciones entre distintas formas de búsqueda de empleo a partir de los datos declarados en 2014 por los titulados universitarios que acabaron sus estudios en el año 2010. Estos datos han sido extraídos de la Encuesta de Inserción Laboral de Titulados Universitarios realizada en 2014 por el INE. Se trata del primer estudio de inserción laboral para este colectivo con objeto de conocer su situación laboral en ese momento y su proceso de inserción en el mercado laboral.
Centraremos la atención en la información recogida sobre aquellos titulados universitarios que, en el momento de la encuesta, todavía no habían encontrado trabajo. En particular, trabajaremos con 11 variables:
- rama: rama a la que pertenecen los estudios universitarios
- nivIngles: nivel de inglés
- nivOrd: nivel de manejo informático
- tiempBusqTr: tiempo buscando empleo
- fAnuncios: ha buscado empleo a través de anuncios
- fINEM: ha buscado empleo en las oficinas de empleo del INEM
- fETTs: ha buscado empleo en la empresas de trabajo temporal (ETT)
- fContactos: ha buscado empleo utilizando sus contactos personales
- fOposic: ha realizado o está preparando alguna oposición
- fAutonomo: ha intentado establecerse como autónomo
- fOtra: ha utilizado cualquier otra forma de búsqueda de trabajo no contemplada en las anteriores variables
Cada variable cuyo nombre comienza por f se refiere a una forma de buscar empleo concreta y sus categorías son 2, sí o no, en función de que la haya usado o no. Así, fAnuncios se refiere a si los encuestados han buscado ofertas de trabajo en anuncios en periódicos, en internet, etc., y tiene dos categorías denominadas fAnuncios_si y fAnuncios_no. Este esquema se mantiene para el resto de variables de ese tipo.
Datos del problema
La información acerca de las 11 variables anteriores se encuentra en el fichero datos.csv. Para leer los datos utilizamos la función read.csv2, en la que se especifica que la primera columna contiene los nombres de las filas (row.names = 1):
datos <- read.csv2("datos.csv", row.names = 1)
dim(datos)## [1] 1217 11Esto es, el objeto datos contiene la información de 11 variables para 1217 encuestados.
summary(datos)## rama nivIngles nivOrd
## Artes-Humanid.:235 ingl_Alto :429 ord_avanzado:812
## Ciencias :160 ingl_Bajo : 77 ord_basico :269
## Ingen.-Arq. :234 ingl_Medio:594 ord_experto :136
## Salud : 41 ingl_No :117
## Social-Jurid. :547
##
## tiempBusqTr fAnuncios fINEM fETTs
## <3meses : 42 fAnuncios_no: 160 fINEM_no:324 fETTs_no:706
## >2años :915 fAnuncios_si:1057 fINEM_si:893 fETTs_si:511
## de1.5a2años: 81
## de1a1.5años: 76
## de3a6meses : 36
## de6a12meses: 67
## fContactos fOposic fAutonomo fOtra
## fContactos_no:494 fOposic_no:738 fAutonomo_no:1125 fOtra_no:1016
## fContactos_si:723 fOposic_si:479 fAutonomo_si: 92 fOtra_si: 201
##
##
##
## Se han considerado, por tanto, 5 ramas de conocimiento, 4 niveles de inglés, 3 niveles de conocimientos de informática, 6 intervalos de tiempos de búsqueda del primer empleo y 2 posibilidades (sí o no) para las 7 variables restantes relativas a la forma de buscar empleo.
Las primeras 4 variables (rama, nivIngles, nivOrd y tiempBusqTr) se pueden utilizar como suplementarias. De esta forma, no intervienen en los resultados del análisis de correspondencias múltiple (ACM), sino que se añaden después para ampliar las conclusiones.
Las variables usadas para llevar a cabo el ACM son las 7 variables dicotómicas relativas a las formas utilizadas para buscar empleo. A estas 7 variables les corresponden, por tanto, 14 categorías, de modo que la inercia total asociada a ellas será \(14/7 - 1 = 1\) (la expresión general para la inercia total en el caso de \(p\) variables con un total de \(K\) categorías es \(K/p - 1\), que siempre valdrá 1 si todas las variables son dicotómicas).
A continuación mostramos las respuestas de los 5 primeros entrevistados (filas 1 a 5 del dataframe datos) para las 7 variables sobre la forma de buscar empleo (columnas 5 a 11). Observe que hay entrevistados que afirman usar más de una forma:
datos[1:5, 5:11]## fAnuncios fINEM fETTs fContactos fOposic
## i_0001 fAnuncios_si fINEM_si fETTs_no fContactos_si fOposic_no
## i_0002 fAnuncios_si fINEM_no fETTs_no fContactos_no fOposic_no
## i_0003 fAnuncios_si fINEM_no fETTs_no fContactos_si fOposic_no
## i_0004 fAnuncios_si fINEM_si fETTs_no fContactos_si fOposic_no
## i_0005 fAnuncios_si fINEM_si fETTs_no fContactos_si fOposic_no
## fAutonomo fOtra
## i_0001 fAutonomo_no fOtra_no
## i_0002 fAutonomo_no fOtra_no
## i_0003 fAutonomo_no fOtra_no
## i_0004 fAutonomo_no fOtra_no
## i_0005 fAutonomo_si fOtra_noEl ACM se puede llevar a cabo usando los paquetes ca o FactoMineR. Usaremos, principalmente, este último junto con factoextra para visualizar algunos resultados.
ACM con FactoMineR sin categorías suplementarias
Una vez instalado el paquete FactoMineR con install.packages("FactoMineR"), se usa la función MCA incluida en dicho paquete para aplicar el ACM. La sintaxis FactoMineR::MCA(...) evita tener que cargar previamente el paquete con library, pero obliga a escribir el nombre del paquete seguido con :: cada vez que se use una función del mismo. La función MCA se aplica sobre los datos correspondientes a las variables cualitativas referidas a la forma de buscar empleo (variables 5 a 11 del objeto datos, esto es, datos[, 5:11]). Por defecto, la función MCA genera la información completa de las 5 primeras dimensiones. Si se desea generar un número diferente, debe incluir el argumento ncp. Por ejemplo, con ncp = 6 genera la información de las 6 primeras dimensiones. Los resultados se deben guardar en un objeto (en nuestro caso, res.mca) para poder extraer posteriormente la información que se desee.
res.mca <- FactoMineR::MCA(datos[, 5:11])


Por defecto, además de guardar los resultados del ACM en el objeto res.mca, el código anterior proporciona tres gráficos, para las categorías, los individuos y las variables, en el espacio de las primeras dos dimensiones, que son las que mayor porcentaje de inercia explican. Estos gráficos se interpretarán más adelante. Además, también se verá cómo obtener gráficos similares en el espacio determinado por otras dimensiones.
Los principales resultados (inercias, contribuciones y cuadrados de las correlaciones) se pueden visualizar aplicando la función summary al objeto res.mca. Por defecto, proporciona la información para los 10 primeros individuos, las 10 primeras categorías y las 3 primeras dimensiones. Para que la salida incluya todas las categorías utilizaremos el argumento nbelements = Inf y para que no incluya a ningún individuo, por ser demasiados, añadiremos nbind = 0. Para mostrar un número diferente de dimensiones, debe usar el argumento ncp.
summary(res.mca, nbelements = Inf, nbind = 0)##
## Call:
## FactoMineR::MCA(X = datos[, 5:11])
##
##
## Eigenvalues
## Dim.1 Dim.2 Dim.3 Dim.4 Dim.5 Dim.6
## Variance 0.231 0.159 0.149 0.140 0.117 0.106
## % of var. 23.143 15.925 14.889 14.017 11.734 10.556
## Cumulative % of var. 23.143 39.068 53.957 67.975 79.709 90.264
## Dim.7
## Variance 0.097
## % of var. 9.736
## Cumulative % of var. 100.000
##
## Categories
## Dim.1 ctr cos2 v.test Dim.2 ctr cos2
## fAnuncios_no | 1.740 24.567 0.458 23.605 | -0.222 0.582 0.007
## fAnuncios_si | -0.263 3.719 0.458 -23.605 | 0.034 0.088 0.007
## fINEM_no | 1.059 18.414 0.407 22.234 | 0.345 2.846 0.043
## fINEM_si | -0.384 6.681 0.407 -22.234 | -0.125 1.032 0.043
## fETTs_no | 0.565 11.421 0.441 23.148 | 0.105 0.579 0.015
## fETTs_si | -0.780 15.779 0.441 -23.148 | -0.146 0.800 0.015
## fContactos_no | 0.653 10.695 0.292 18.832 | -0.208 1.582 0.030
## fContactos_si | -0.446 7.308 0.292 -18.832 | 0.142 1.081 0.030
## fOposic_no | -0.062 0.143 0.006 -2.679 | 0.654 23.243 0.658
## fOposic_si | 0.095 0.221 0.006 2.679 | -1.007 35.811 0.658
## fAutonomo_no | 0.037 0.079 0.017 4.532 | -0.018 0.027 0.004
## fAutonomo_si | -0.454 0.964 0.017 -4.532 | 0.220 0.329 0.004
## fOtra_no | -0.005 0.001 0.000 -0.421 | -0.266 5.285 0.357
## fOtra_si | 0.027 0.008 0.000 0.421 | 1.343 26.714 0.357
## v.test Dim.3 ctr cos2 v.test
## fAnuncios_no -3.014 | 0.001 0.000 0.000 0.014 |
## fAnuncios_si 3.014 | 0.000 0.000 0.000 -0.014 |
## fINEM_no 7.250 | 0.359 3.290 0.047 7.538 |
## fINEM_si -7.250 | -0.130 1.194 0.047 -7.538 |
## fETTs_no 4.324 | 0.226 2.853 0.071 9.280 |
## fETTs_si -4.324 | -0.313 3.942 0.071 -9.280 |
## fContactos_no -6.008 | -0.455 8.073 0.142 -13.123 |
## fContactos_si 6.008 | 0.311 5.516 0.142 13.123 |
## fOposic_no 28.293 | 0.053 0.165 0.004 2.307 |
## fOposic_si -28.293 | -0.082 0.255 0.004 -2.307 |
## fAutonomo_no -2.195 | -0.223 4.422 0.610 -27.227 |
## fAutonomo_si 2.195 | 2.730 54.068 0.610 27.227 |
## fOtra_no -20.827 | 0.183 2.679 0.169 14.339 |
## fOtra_si 20.827 | -0.924 13.543 0.169 -14.339 |
##
## Categorical variables (eta2)
## Dim.1 Dim.2 Dim.3
## fAnuncios | 0.458 0.007 0.000 |
## fINEM | 0.407 0.043 0.047 |
## fETTs | 0.441 0.015 0.071 |
## fContactos | 0.292 0.030 0.142 |
## fOposic | 0.006 0.658 0.004 |
## fAutonomo | 0.017 0.004 0.610 |
## fOtra | 0.000 0.357 0.169 |El número total de dimensiones que se obtienen con un ACM es igual al número total de categorías (\(K = 14\)) menos el número de variables cualitativas (\(p = 7\)) consideradas en el análisis, en este caso, \(K - p = 14 - 7 = 7\). A la hora de emplear los resultados del ACM para obtener conclusiones, con el fin de disminuir la complejidad del problema a analizar, se consideran solo los resultados relativos a unas pocas dimensiones, aquellas con mayor inercia que, además, recojan un porcentaje adecuado de la inercia total del conjunto completo de datos. Una forma usual de proceder es analizar aquellas cuya inercia sea mayor que la inercia media por dimensión (inercia total/número de dimensiones), cantidad que, en este caso, vale \(1/p = 1/7 = 0.143\).
En la salida anterior aparece, en primer lugar, una tabla para las inercias (valores propios o Eigenvalues en inglés) de las dimensiones ordenadas de mayor a menor. La inercia se muestra en la fila denominada Variance. De acuerdo con el criterio anterior, procederemos a analizar las 3 primeras dimensiones, dado que sus inercias son mayores que \(0.143\). En la fila % of var. aparece el porcentaje de la varianza total recogido por cada dimensión. Por último, la fila Cumulative % of var. recoge el porcentaje anterior acumulado. Así, con las tres primeras dimensiones se cubre el 53.957% de la inercia total.
La anterior salida con los resultados del ACM también proporciona información sobre las categorías en las tres primeras dimensiones:
La primera columna son las puntuaciones o coordenadas en cada dimensión. Nos permite saber, por ejemplo, si cada categoría se relaciona de forma positiva o negativa con la dimensión.
ctrrecoge las contribuciones de las categorías a una dimensión, esto es, el porcentaje de inercia de la dimensión que es explicado por cada categoría (contribución absoluta). La suma de esta columna, por tanto, es 100. Se observa que las categorías que más inercia consiguen explicar de la dimensión 1 son las correspondientes a las variables relativas a la búsqueda de empleo mediante anuncios (fAnuncios), servicios públicos de empleo (fINEM), empresas de trabajo temporal (fETTs) y contactos personales (fContactos). Todas ellas conjuntamente explican el 98.6% de la inercia de la dimensión 1. En la dimensión 2 son las categorías de las variables relativas a la búsqueda de empleo mediante oposición (fOposic) u otra forma no especificada en la encuesta (fOtra) las que más inercia consiguen explicar, siendo del 91.1% entre las cuatro categorías de estas dos variables. Finalmente, en la dimensión 3, las categorías que más inercia explican (el 58.5%) son las de la variable relativa a la búqueda de empleo mediante autoempleo (fAutonomo). La inercia de esta dimensión también viene explicada, en bastante menor medida, por las categorías de fOtra (16%) y de fContactos (14%).cos2es la contribución de la dimensión a las categorías y viene dada por la proporción de inercia de una categoría explicada por una dimensión (contribución relativa). Es, por tanto, una medida de lo bien representada que queda la categoría por cada dimensión. Así, podemos ver que la dimensión 1 recoge más del 40% de la inercia de cada una de las categorías relativas a las variables fAnuncios, fINEM y fETTs, y casi el 30% de fContactos; del resto de variables apenas recoge inercia. La dimensión 2 recoge cerca del 66% de la inercia de cada categoría de la variable fOposic, el 36% en el caso de las categorías de fOtra y prácticamente nada de la inercia del resto. Respecto a la dimensión 3, se puede observar que recoge el 61% de la inercia de cada categoría de fAutonomo y menos del 20% de la inercia de las restantes categorías. Dadas las dos dimensiones que definen un plano, la suma de la contribución relativa de cada una a cierta categoría permite obtener la calidad de la representación de dicha categoría en el plano. Lógicamente, se puede extender al conjunto de las tres dimensiones.v.test. Si su valor absoluto es mayor que 2 se considera que la coordenada es significativamente distinta de 0.
Finalmente, aparece una matriz con los valores de eta2 que miden el grado de relación de cada variable con cada dimensión. Así, se puede comprobar que la primera dimensión (Dim.1) está muy relacionada con varias formas de buscar empleo: anuncios, INEM, ETT y contactos. La segunda dimensión está especialmente relacionada con la preparación de oposiciones y con cualquier otra forma de búsqueda que no esté incluida en las variables consideradas, y la tercera con establecerse como autónomo.
Si se quiere que el objeto res.mca guarde solo la información relativa a las tres primeras dimensiones que se han determinado de interés, hay que introducir el argumento ncp = 3 de la siguiente forma:
res.mca <- FactoMineR::MCA(datos[, 5:11], ncp = 3, graph = FALSE) Observe que ahora se ha elegido la opción de no dibujar gráficos (graph = FALSE) puesto que estos ya se han representado anteriormente.
Gráficos para el ACM
Parte de los resultados anteriores se pueden visualizar con el paquete factoextra, que deberá instalar si no lo ha hecho previamente.
1. Gráficos para el porcentaje de inercia de cada dimensión
factoextra::fviz_screeplot(res.mca, addlabels = TRUE,
title = "Porcentaje de la inercia total en cada dimensión", ylim = c(0, 25))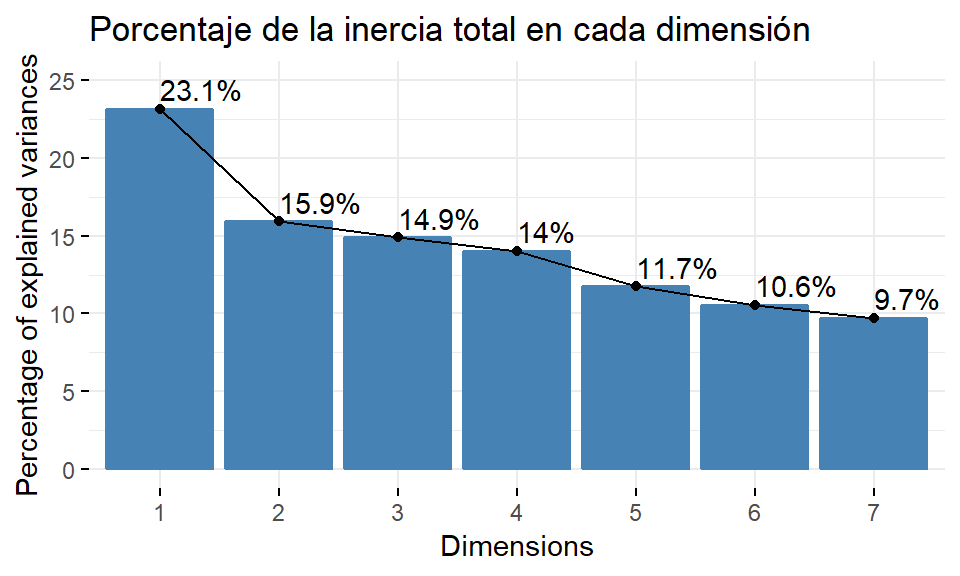
2. Gráficos para las contribuciones de las categorías (ctr) a una dimensión
A continuación representamos tres gráficos con las contribuciones de las categorías (ctr, ordenadas de mayor a menor) a cada una de las tres dimensiones seleccionadas. En los gráficos aparece una línea discontinua que corresponde al valor que tendría la contribución de cualquier categoría si la inercia de la dimensión estuviera uniformemente repartida entre ellas. Así, si todas las categorías contribuyeran en la misma proporción, esa contribución sería \(100\%/14=7.14\%\). Para interpretar una dimensión puede ser un buen criterio considerar aquellas categorías que tengan una contribución superior a esa cantidad.
factoextra::fviz_contrib(res.mca, choice="var", axes = 1, fill="blue", title = "Contribución de las categorías a la dimensión 1")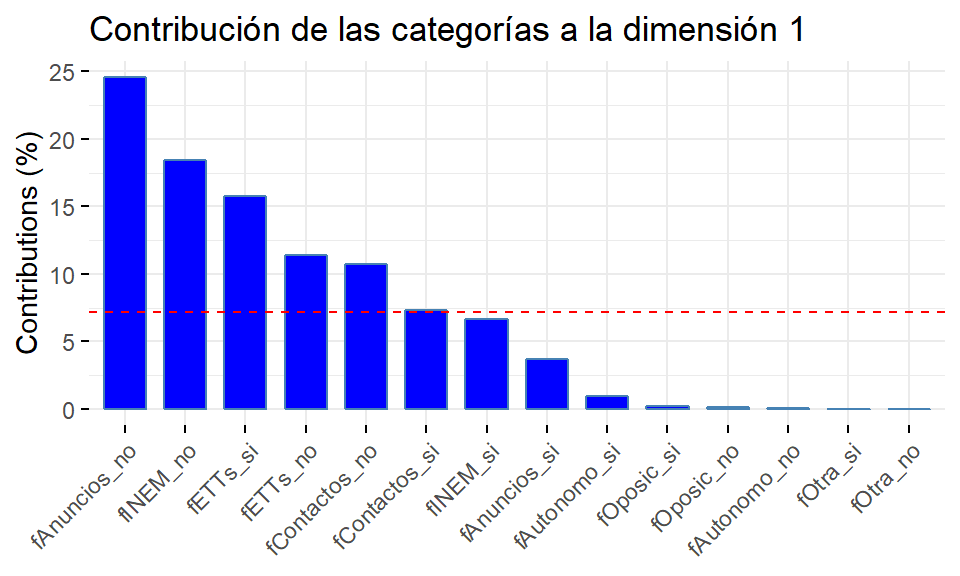
factoextra::fviz_contrib(res.mca, choice="var", axes = 2, fill="blue", title = "Contribución de las categorías a la dimensión 2")
factoextra::fviz_contrib(res.mca, choice="var", axes = 3, fill="blue", title = "Contribución de las categorías a la dimensión 3")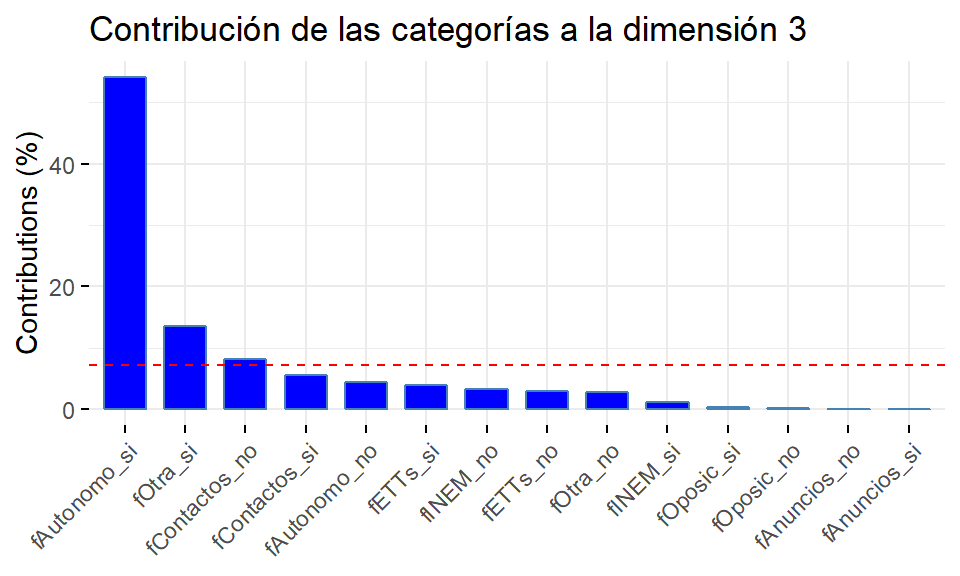
3. Gráficos para las contribuciones de las categorías (ctr) a varias dimensiones
Los siguientes gráficos permiten visualizar la contribución de las categorías (ctr) a los subespacios generados por dos o tres dimensiones. La línea discontinua representa lo mismo que en los gráficos anteriores, pero ahora para el 100% de la inercia del subespacio correspondiente.
factoextra::fviz_contrib(res.mca, choice="var", axes = c(1,2), fill="brown", title = "Contribución de las categorías al plano 1-2")
factoextra::fviz_contrib(res.mca, choice="var", axes = c(1,3), fill="brown", title = "Contribución de las categorías al plano 1-3")
factoextra::fviz_contrib(res.mca, choice="var", axes = c(2,3), fill="brown", title = "Contribución de las categorías al plano 2-3")
factoextra::fviz_contrib(res.mca, choice="var", axes = c(1,2,3), fill="brown", title = "Contribución de las categorías al subespacio 1-2-3")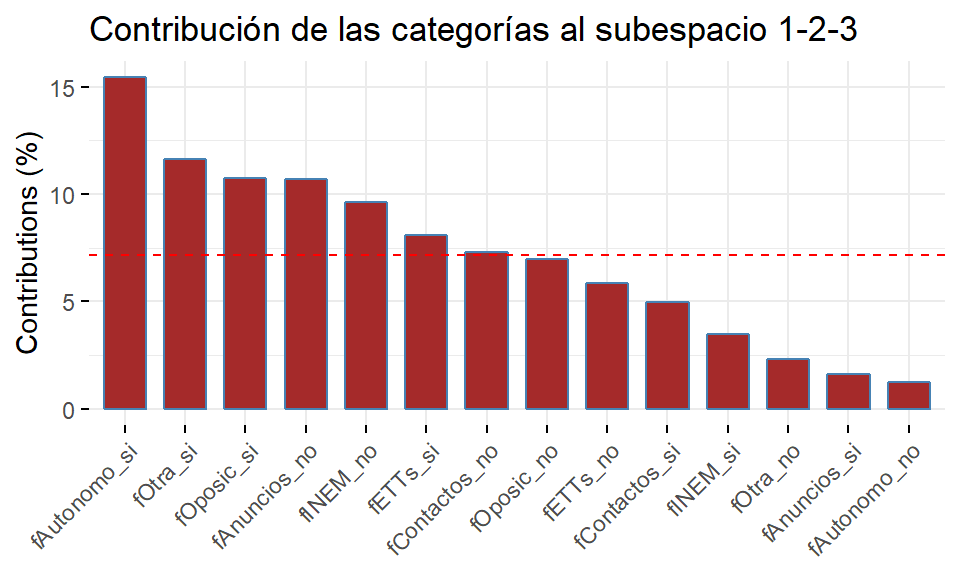
4. Gráficos para la calidad de representación de las categorías (cos2) en el espacio formado por varias dimensiones
También se puede realizar un gráfico para la calidad de la representación de las categorías (cos2) en el plano formado por el par de dimensiones que se desee o en el espacio de tres o más dimensiones:
factoextra::fviz_cos2(res.mca, choice="var", axes = c(1,2), fill = "orange", title = "Cos2 de las categorías en el plano 1-2")
factoextra::fviz_cos2(res.mca, choice="var", axes = c(1,3), fill = "orange", title = "Cos2 de las categorías en el plano 1-3")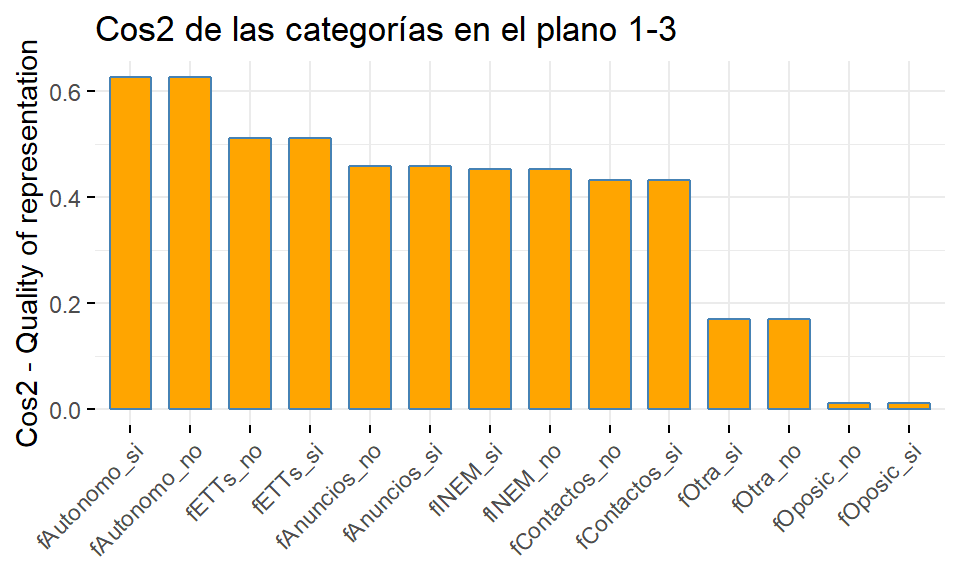
factoextra::fviz_cos2(res.mca, choice="var", axes = c(2,3), fill = "orange", title = "Cos2 de las categorías en el plano 2-3")
De la observación del primer gráfico del cos2 se obtiene que, en el plano 1-2, ninguna categoría de fAutonomo estaría bien representada. En el plano 1-3 no lo estarían las de fOposic y fOtra, y en el plano 2-3 las de fAnuncios, fETTs, fINEM y fContactos. Fíjese que ninguno de los cos2 correspondientes a los casos citados llega al valor de 0.2.
5. Gráficos para la nube de categorías seleccionadas por algún criterio
El gráfico de las categorías proyectadas sobre el espacio bidimensional correspondiente a las dimensiones 1 y 2, que fue representado anteriormente por MCA, se construye a partir de las puntuaciones o coordenadas en esas dimensiones mostradas con summary. Este gráfico también se puede obtener de la siguiente forma:
plot(res.mca, axes = c(1, 2), choix = "ind", label = "var", invisible = "ind", cex = 0.8, title = "Nube proyectada de las categorías")
Para obtener ayuda sobre los argumentos de este gráfico puede teclear en la consola de R ?? plot.MCA.
Ese gráfico puede resultar un poco confuso debido a la gran cantidad de elementos que contiene. En la salida de summary y en uno de los gráficos anteriores obtenidos con fviz_contrib, se observa, por ejemplo, que fAnuncions_no, fOposic_si, fINEM_no, fOtra_si, fETTs_si, fOposic_no, fETTs_no y fContactos_no son las categorías que más contribuyen al plano 1-2. Se puede volver a dibujar el gráfico anterior con plot pero restringiendo a que solo estas 8 categorías aparezcan en él introduciendo el argumento selectMod = "contrib 8".
plot(res.mca, axes = c(1, 2), choix = "ind", label = "var", invisible = "ind", selectMod = "contrib 8", cex = 0.8, title = "Nube proyectada con las categorías que más contribuyen al plano")
Análogamente, en el gráfico se pueden dejar solo las categorías mejor representadas en el plano de las dos primeras dimensiones. Por ejemplo, si se desean 8 hay que incluir el argumento selectMod = "cos2 8". Nótese que, en los dos gráficos simplificados, no aparecen exactamente las mismas categorías.
plot(res.mca, axes = c(1, 2), choix = "ind", label = "var", invisible = "ind", selectMod = "cos2 8", cex = 0.8, title = "Nube proyectada de las categorías mejor representadas")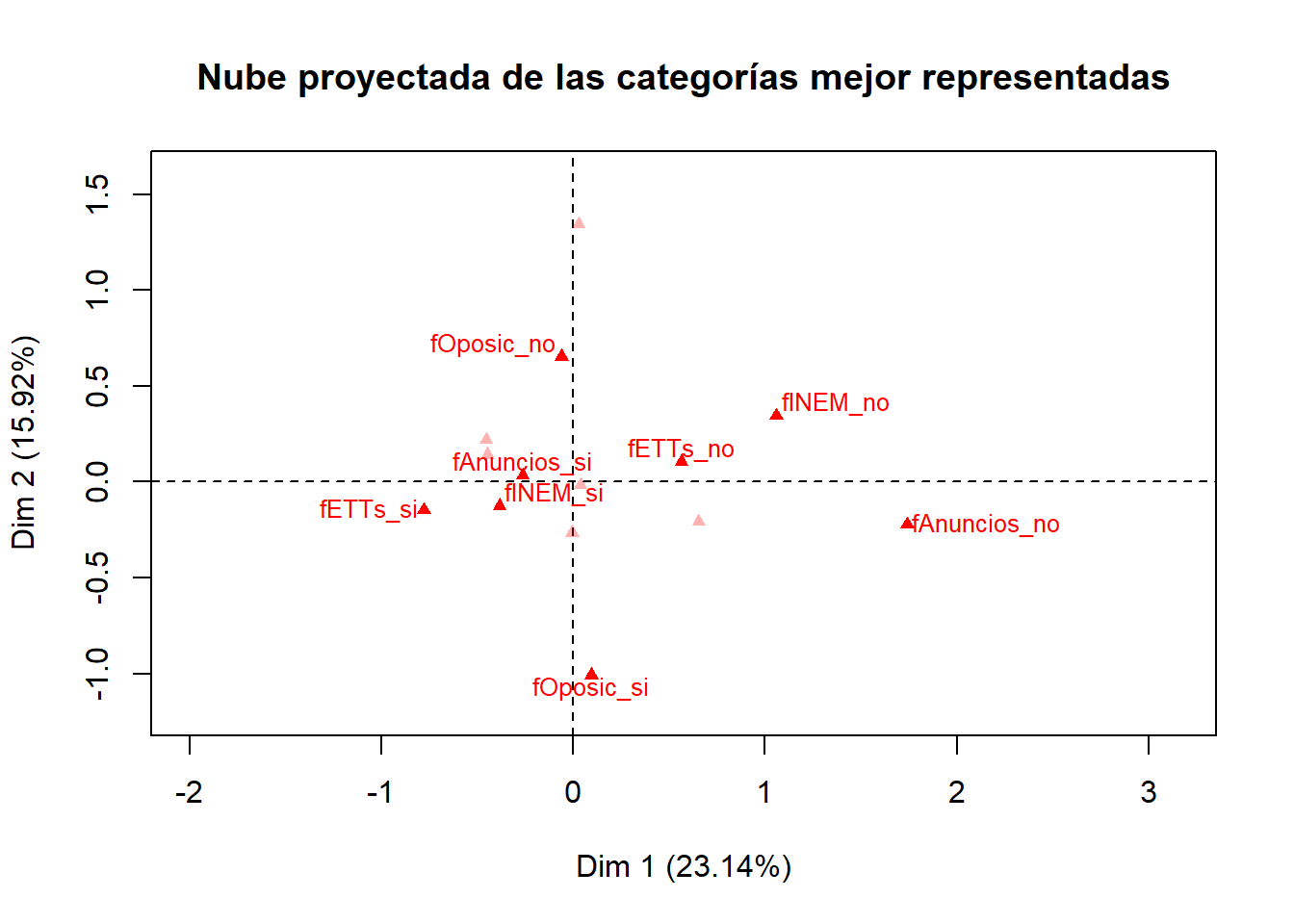
Se pueden dibujar gráficos análogos sobre otros planos, por ejemplo:
plot(res.mca, axes = c(1, 3), choix = "ind", label = "var", invisible = "ind", cex = 0.8, title = "Nube proyectada de las categorías")
plot(res.mca, axes = c(2, 3), choix = "ind", label = "var", invisible = "ind", cex = 0.8, title = "Nube proyectada de las categorías")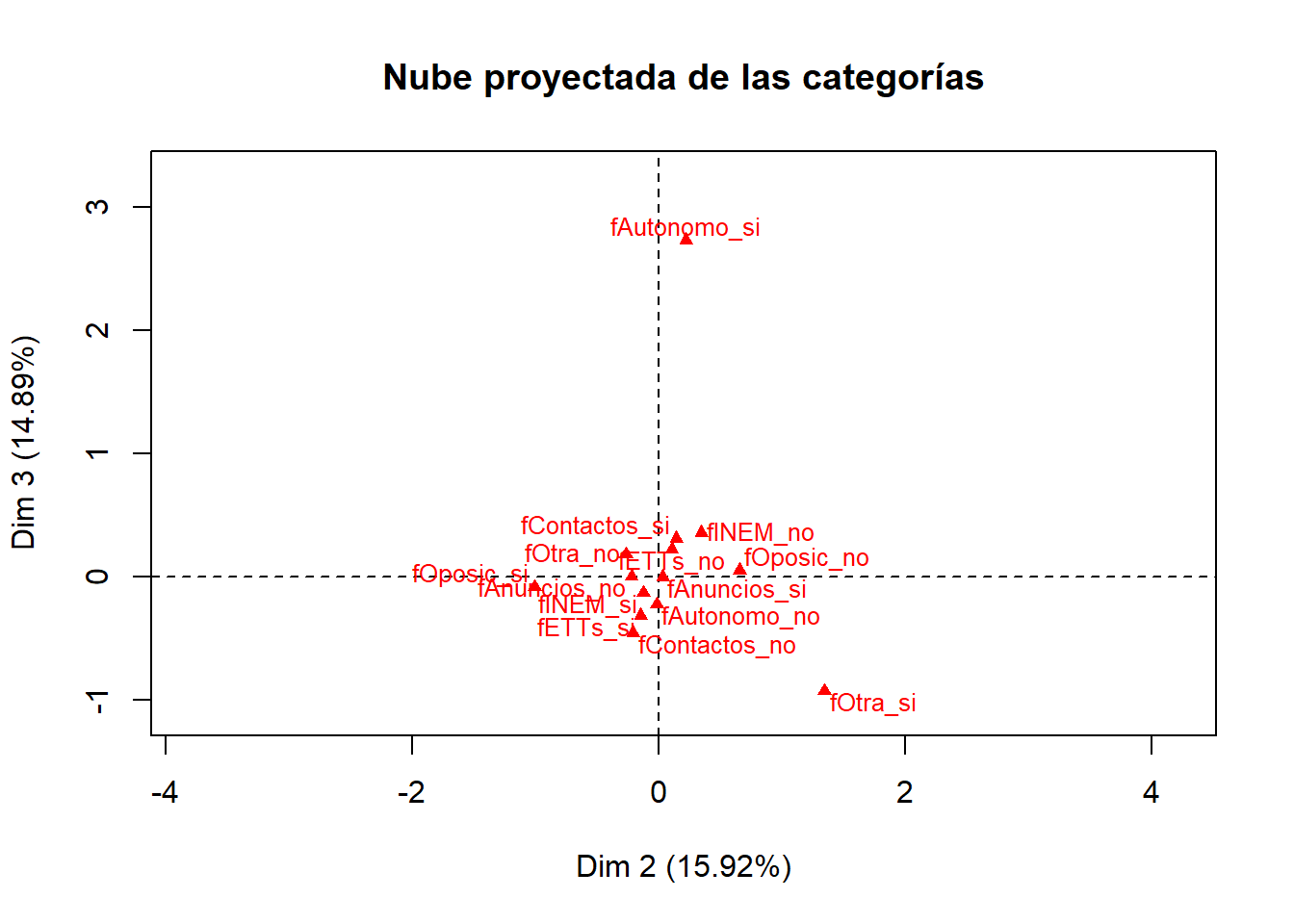
Una versión mejorada de los gráficos asociados a un análisis ACM se puede obtener con el paquete factoextra. En estos gráficos, el color de las categorías depende de la contribución a las dos dimensiones representadas. Veamos, por ejemplo, cómo dibujar con factoextra algunos de los gráficos anteriores:
factoextra::fviz_mca_var(res.mca, axes=c(1,2), choice="var.cat", repel=T,
gradient.cols=c("white","white","orange","blue","black"),
col.var="contrib",
title = "Nube proyectada de las categorías según su contribución al plano 1-2")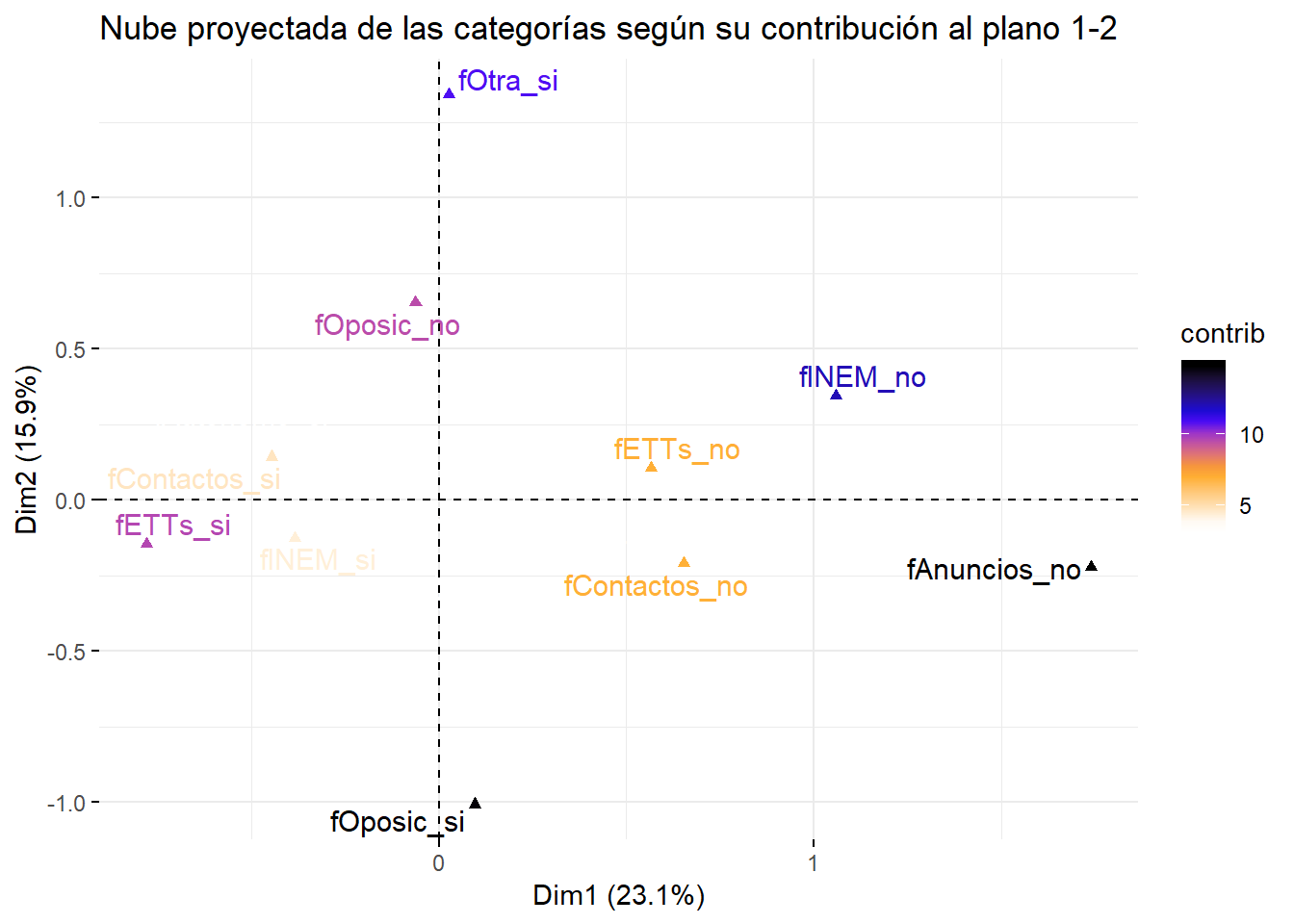
factoextra::fviz_mca_var(res.mca, axes=c(1,3), choice="var.cat", repel=T,
gradient.cols=c("white","white","orange","blue","black"),
col.var="contrib",
title = "Nube proyectada de las categorías según su contribución al plano 1-3")
factoextra::fviz_mca_var(res.mca, axes=c(2,3), choice="var.cat", repel=T,
gradient.cols=c("white","white","orange","blue","black"),
col.var="contrib",
title = "Nube proyectada de las categorías según su contribución al plano 2-3")
De forma similar, se pueden representar las categorías con colores que dependen de lo bien representadas (cos2) que estén en ese plano. Observe que en los gráficos siguientes se ha elegido una gradación de colores en la que el blanco se ha asignado a categorías muy mal representadas. La intensidad del color de una categoría y, por tanto, su visibilidad en los gráficos aumenta con el valor del cos2.
factoextra::fviz_mca_var(res.mca, axes = c(1,2), choice = "var.cat", repel = T,
gradient.cols = c("white", "yellow", "orange", "blue", "black"),
col.var = "cos2",
title = "Nube proyectada de las categorías en el plano 1-2 según cos2")
Una vez eliminadas del gráfico las categorías mal representadas, se pueden extraer algunas conclusiones. Aquellas categorías que se encuentren muy alejadas del origen son elegidas menos frecuentemente. Por ejemplo, la proporción de individuos que utilizan anuncios (fAnuncios_si) es mayor que la de los que no (fAnuncios_no). La proporción de los que preparan oposiciones (fOposic_si) es menor que la de los que no (fOposic_no), aunque en este caso la diferencia entre ambas proporciones no es tan alta. Estos mismos resultados se pueden observar sobre los datos originales:
table(datos$fAnuncios)##
## fAnuncios_no fAnuncios_si
## 160 1057table(datos$fOposic)##
## fOposic_no fOposic_si
## 738 479Observe que las categorías fINEM_si y fAnuncios_si están bastante cercanas entre sí. Esto indica que sobre el total de invidividuos que utilizan al menos una de esas dos formas de búsqueda, la proporción de los que utilizan ambas es bastante elevada. Sin embargo, fOposic_si y fAnuncios_si están más alejadas entre sí, porque sobre el total de invidividuos que utilizan al menos una de estas dos formas de búsqueda, la proporción de los que utilizan ambas es mucho menos elevada. Para comprobarlo observe las siguientes tablas:
table(datos$fAnuncios, datos$fINEM)##
## fINEM_no fINEM_si
## fAnuncios_no 83 77
## fAnuncios_si 241 816table(datos$fAnuncios, datos$fOposic)##
## fOposic_no fOposic_si
## fAnuncios_no 76 84
## fAnuncios_si 662 395La primera proporción descrita vale \(816/(77+241+816) \approx 0.72\) mientras que la segunda vale \(395/(84+662+395) \approx 0.35\).
Centrando la atención en la dimensión 1, se observa que el lado derecho se asocia con no usar las formas de búsqueda de empleo relacionadas con esa dimensión y el lado izquierdo con su uso. De hecho, la forma correcta de interpretar las proyecciones de las categorías en el plano debe ser la siguiente: cuanto más a la derecha se sitúe la proyección de un individuo en ese eje, menos de esas formas de búsqueda de empleo tenderá a utilizar y conforme nos movemos hacia la izquierda empiezan a ir usando alguna de ellas. Más adelante construiremos una variable suplementaria que permitirá una mejor visualización de este hecho sobre una nube proyectada de individuos.
Si nos fijamos en la dimensión 2 se observa que, vistas desde el origen, fOtra_no y fOposic_si están alineadas. Al estar la segunda más lejos del origen que la primera indica que quien prepara oposiciones tenderá a no utilizar otras formas de búsqueda de empleo distintas de las consideradas explícitamente en el cuestionario (fOtra_no). A su vez indica que los que opositan serán mucho menos en número que los individuos que seleccionaron fOtra_no. Análogamente, las posiciones de fOposic_no y fOtra_si señalan que la mayoría de los que seleccionan fOtra_si son una pequeña parte de los que no opositan. Puede comprobar esto en la siguiente tabla de frecuencias derivada de los datos originales:
table(datos$fOtra, datos$fOposic)##
## fOposic_no fOposic_si
## fOtra_no 594 422
## fOtra_si 144 57table(datos$fContactos, datos$fAutonomo)##
## fAutonomo_no fAutonomo_si
## fContactos_no 472 22
## fContactos_si 653 70Para otros planos tendríamos los siguientes gráficos:
factoextra::fviz_mca_var(res.mca, axes = c(1, 3), choice = "var.cat", repel = T,
gradient.cols = c("white", "yellow", "orange", "blue", "black"),
col.var = "cos2",
title = "Nube proyectada de las categorías en el plano 1-3 según cos2")
factoextra::fviz_mca_var(res.mca, axes = c(2, 3), choice = "var.cat", repel = T,
gradient.cols = c("white", "yellow", "orange", "blue", "black"),
col.var = "cos2",
title = "Nube proyectada de las categorías en el plano 2-3 según cos2")
6. Gráficos para el coeficiente eta2
Los gráficos de los coeficientes eta2 de las variables con diferentes dimensiones serían:
plot(res.mca, axes = c(1, 2), choix = "var", cex = 0.8,
title = "Coeficiente eta2 de cada variable con las dimensiones 1 y 2")
plot(res.mca, axes = c(1, 3), choix = "var", cex = 0.8,
title = "Coeficiente eta2 de cada variable con las dimensiones 1 y 3")
En estos gráficos podemos visualizar los resultados que obtuvimos acerca de las relaciones de las variables con las dimensiones. Así, se puede observar que la primera dimensión está muy relacionada con varias formas de buscar empleo: anuncios, INEM, ETT y contactos. La segunda dimensión está especialmente relacionada con las oposiciones y con fOtra (cualquier forma no incluida explícitamente en las variables consideradas), y la tercera con establecerse como autónomo y en menor medida con fOtra.
7. Gráficos con elipses de concentración de las categorías sobre las nubes de individuos
Los siguientes gráficos nos van a permitir visualizar de forma distinta los resultados obtenidos. Para ello se usarán proyecciones de nubes de individuos a las que se añadirán elipses de concentración de los individuos correspondientes a cada categoría de una determinada variable. Se podrá ver sobre qué dimensión o plano se produce una mayor diferenciación entre las categorías de esa variable.
factoextra::fviz_ellipses(res.mca,ellipse.type="t", axes=c(1,2), c("fINEM", "fETTs", "fAnuncios", "fContactos"), geom = "point")
En estos gráficos se puede observar cómo las elipses de concentración de los puntos correspondientes a las categorías de una cualquiera de las variables elegidas están diferenciadas entre sí horizontalmente, indicando que la dimensión representada en ese eje (dimensión 1 en este caso) discrimina entre ambas categorías de la variable. Esto no es así para la dimensión en el eje vertical (dimensión 2).
factoextra::fviz_ellipses(res.mca,ellipse.type="t", axes=c(1,2), c("fOposic", "fOtra", "fAutonomo"), geom = "point")
En este gráfico se observa cómo las restantes variables no presentan elipses de concentración para sus categorías diferenciadas horizontalmente. Esto es coherente con los resultados anteriores en los que vimos que estas variables no estaban apenas relacionadas con la dimensión 1. Sin embargo, dos de ellas (fOposic y fOtra) presentan elipses de concentración diferenciadas verticalmente. Precisamente esas dos son las variables que mayor coeficiente eta2 tenían con la dimensión 2.
factoextra::fviz_ellipses(res.mca,ellipse.type="t", axes=c(2,3), c("fINEM", "fETTs", "fAnuncios", "fContactos"), geom = "point")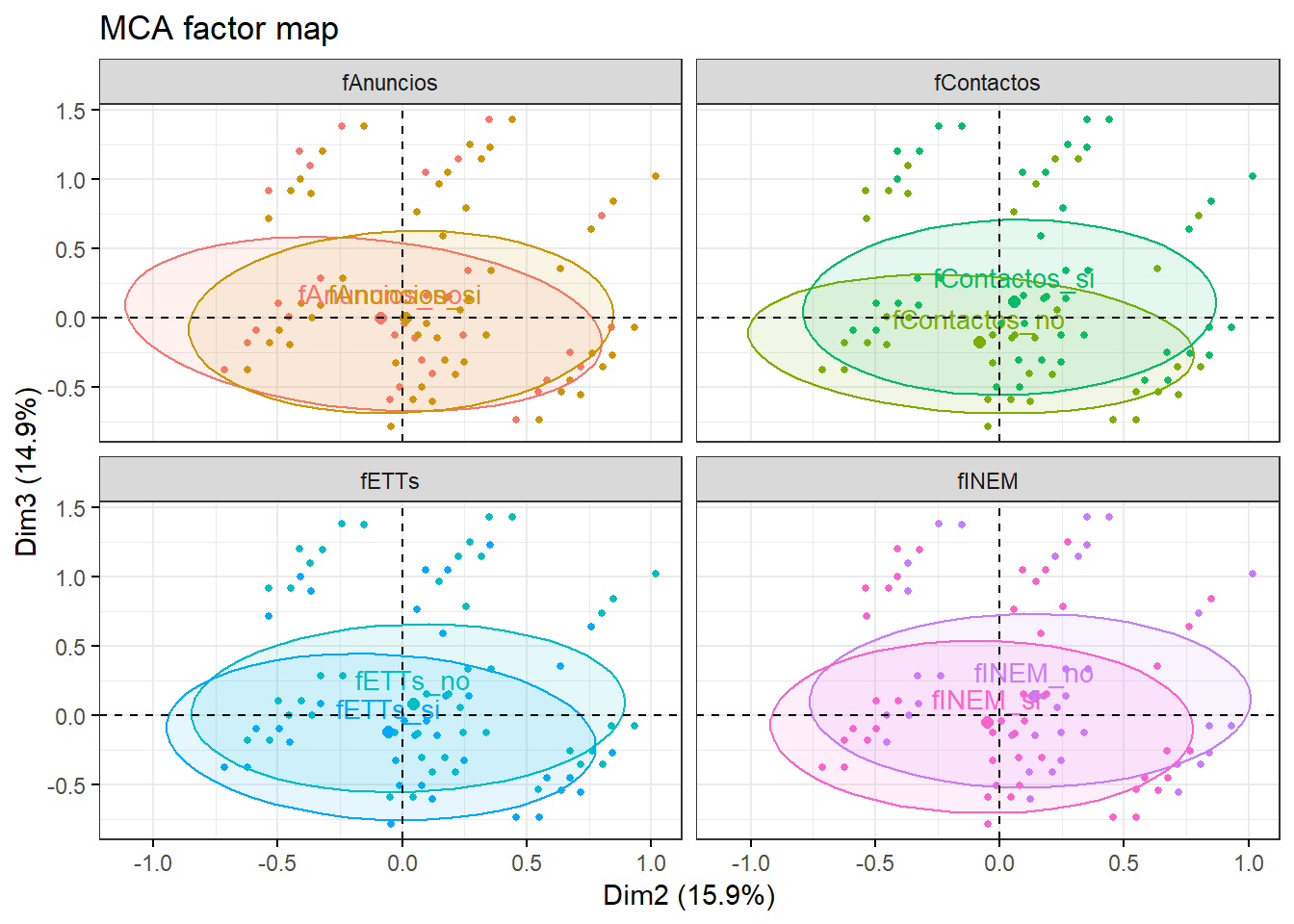
En este gráfico hemos considerado el plano formado por las dimensiones 2 (eje horizontal) y 3 (eje vertical). Se observa que, para las cuatro variables consideradas (relativas a anuncios, contactos, ETT e INEM), las elipses de sus categorías apenas se diferencian (esas variables apenas tenían relación con las dimensiones 2 y 3).
factoextra::fviz_ellipses(res.mca,ellipse.type="t", axes=c(2,3), c("fOposic", "fOtra", "fAutonomo"), geom = "point")## Warning in MASS::cov.trob(data[, vars]): Probable convergence failure Ahora consideramos las tres variables restantes. Como se podía esperar de los coeficientes eta2 obtenidos anteriormente, las elipses se separan verticalmente (dimensión 3) en el caso de fAutonomo, y horizontalmente (dimensión 2) en el caso de fOposic. Como ya vimos fOtra está relacionada tanto con la dimensión 2 como con la dimensión 3, de ahí que las elipses de concentración de sus categorías se diferencien tanto horizontalmente como verticalmente, esto es, a lo largo de la bisectriz del segundo cuadrante.
Ahora consideramos las tres variables restantes. Como se podía esperar de los coeficientes eta2 obtenidos anteriormente, las elipses se separan verticalmente (dimensión 3) en el caso de fAutonomo, y horizontalmente (dimensión 2) en el caso de fOposic. Como ya vimos fOtra está relacionada tanto con la dimensión 2 como con la dimensión 3, de ahí que las elipses de concentración de sus categorías se diferencien tanto horizontalmente como verticalmente, esto es, a lo largo de la bisectriz del segundo cuadrante.
Conclusiones
Los resultados del ACM visualizados en los gráficos anteriores se puede resumir de la siguiente forma:
- La dimensión 1 (23.14% de la inercia total) está relacionada sobre todo con la búsqueda de empleo mediante anuncios, empresas de trabajo temporal, servicios públicos (INEM) y, algo menos, mediante contactos. Asigna, en general, puntuaciones positivas al hecho de no utilizar esos medios y negativas en caso contrario. De hecho, la dimensión 1 está relacionada con la cantidad utilizada de esas formas de búsqueda de empleo. Como ya se comentó, más adelante propondremos una variable suplementaria que clarificará este aspecto.
La dimensión 2 (15.93% de la inercia total) está relacionada principalmente con la búsqueda de empleo mediante oposiciones (puntuaciones, en general, negativas al hecho de prepararlas y positivas a no hacerlo) y, en menor medida, con otras formas no contempladas explícitamente en el cuestionario (puntuaciones, en general, positivas cuando se usan y negativas cuando no). En consecuencia, al opositar se tiende a no utilizar esas otras formas y quién las emplea no suele preparar oposiciones.
Los gráficos en los que aparece la dimensión 2 y las dos categorías de la fOposicion muestran a estas muy alineadas con esa dimensión, y con un valor casi nulo en las demás dimensiones. Como las dimensiones entre sí son ortogonales, desde el punto de visto geométrico, o, traducido ese hecho al campo estadístico, incorreladas, lleva a pensar que fOposicion (bastante relacionada con la dimensión 2) estará poco relacionada con variables como fAnuncios, fINEM, fContactos y fETTs (que estaban bastante relacionadas con la dimensión 1). Esto implica que es muy parecido el comportamiento, entre los que preparan oposiciones y entre los que no, en relación a la búsqueda de trabajo mediante anuncios, INEM, contactos o ETTs.
prop.table(table(datos$fAnuncios, datos$fOposic), 2)## ## fOposic_no fOposic_si ## fAnuncios_no 0.1029810 0.1753653 ## fAnuncios_si 0.8970190 0.8246347prop.table(table(datos$fINEM, datos$fOposic), 2)## ## fOposic_no fOposic_si ## fINEM_no 0.2804878 0.2442589 ## fINEM_si 0.7195122 0.7557411prop.table(table(datos$fContactos, datos$fOposic), 2)## ## fOposic_no fOposic_si ## fContactos_no 0.3821138 0.4425887 ## fContactos_si 0.6178862 0.5574113prop.table(table(datos$fETTs, datos$fOposic), 2)## ## fOposic_no fOposic_si ## fETTs_no 0.5975610 0.5532359 ## fETTs_si 0.4024390 0.4467641
La dimensión 3 (14.89% de la inercia total) está relacionada con la intención o no de establecerse como autónomo, con puntuaciones, en general, positivas para los que sí, y negativas para los que no.
Razonamientos análogos a los anteriores llevan a pensar en la escasa relación entre fAutonomo y todas las variables citadas antes. Se puede observar que los individuos que sí desean trabajar autónomamente, también buscan oportunidades, incluso con una frecuencia algo superior la media, mediante anuncios o contactos, y que tienden a rechazar, también con una frecuencia más alta que la media, la posibilidad de preparar oposiciones.
ACM con FactoMineR incluyendo categorías suplementarias
Una vez analizados los resultados obtenidos, puede resultar de interés representar en el gráfico de las categorías otras que no hayan intervenido en el análisis, por no ser formas de buscar empleo, pero que correspondan a variables que pueden tener relación con ellas. En particular, la rama de la titulación, el nivel de inglés y de informática y el tiempo que llevan buscando empleo (son las cuatro primeras variables del data.frame datos), aunque aquí se estudiará solo la rama de la titulación.
Además, construimos dos nuevas variables suplementarias, derivadas especialmente de la observación del gráfico de la nube de categorías en el plano de la dimensión 1-2, y que tienen que ver con el número de formas usadas a la hora de buscar empleo y con el orden de utilización de las mismas.
1. Variable suplementaria: rama de conocimiento
Representamos gráficamente las distintas ramas de conocimiento de los estudios cursados por los individuos en cada uno de los tres planos que se pueden formar con las tres primeras dimensiones.
res.mca <- FactoMineR::MCA(datos[, c(1, 5:11)], quali.sup = 1, graph = FALSE)
factoextra::fviz_mca_var(res.mca, axes=c(1,2), choice="var.cat", repel=T,
gradient.cols=c("white","yellow","orange","blue","black"),
col.var="cos2")
factoextra::fviz_mca_var(res.mca, axes=c(2,3), choice="var.cat", repel=T,
gradient.cols=c("white","yellow","orange","blue","black"),
col.var="cos2")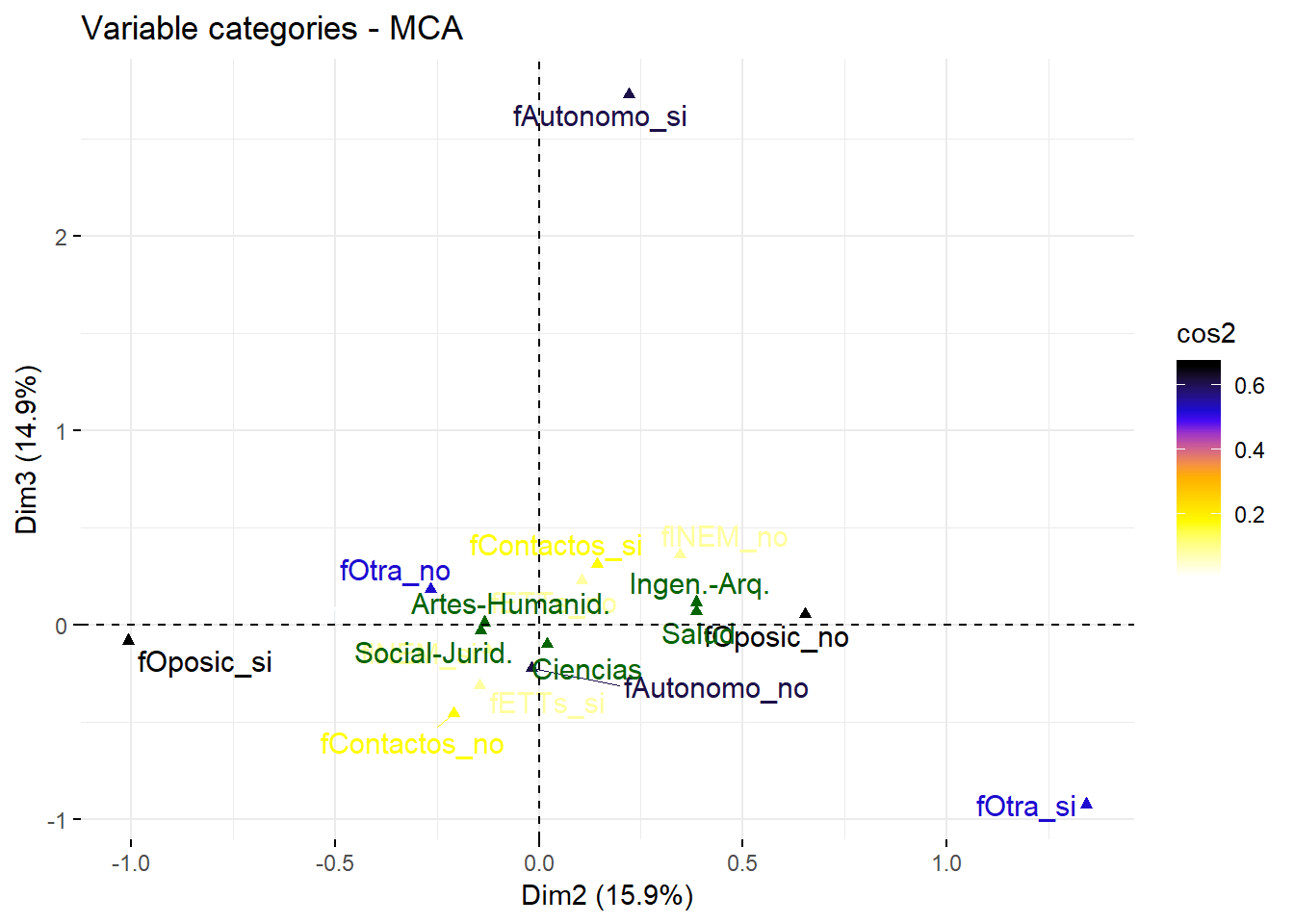
Para obtener conclusiones sobre los titulados de una rama con respecto a una forma de buscar empleo debe proceder de la siguiente manera. Se comparan las distancias en el gráfico de la rama respecto a las categorías que supongan usar o no esa forma de empleo. Tenga en cuenta que la escala de los dos ejes del gráfico debe ser la misma porque, en caso contrario, el gráfico es engañoso. Además, las categorías suplementarias deben estar bien representadas en el plano para que se puedan obtener conclusiones fiables. Esto se mide, al igual que en el caso de las categorías activas, con cos2. En este caso, como se puede comprobar a continuación, no están bien representadas.
rowSums(res.mca$quali.sup$cos2[,1:2]) # cos2 en el plano 1-2## Artes-Humanid. Ciencias Ingen.-Arq. Salud Social-Jurid.
## 0.005525862 0.006260022 0.041029764 0.006589731 0.021583288rowSums(res.mca$quali.sup$cos2[,2:3]) # cos2 en el plano 2-3## Artes-Humanid. Ciencias Ingen.-Arq. Salud Social-Jurid.
## 0.004249796 0.001591468 0.038652843 0.005382757 0.017394156Una menor distancia entre una categoría no suplementaria y una suplementaria indica una tendencia mayor de esos titulados a seleccionarla. Por ejemplo, en el gráfico, la rama de Ciencias está mucho más cerca de fINEM_si que de fINEM_no indicando que los licenciados en esa rama que utilizan INEM son más que los que no lo hacen. Se observa que, en general, ocurre lo mismo en el resto de ramas. Esto mismo sucede, por ejemplo, para la búsqueda de empleo a través de anuncios. En todo caso, es aconsejable siempre verificar estas conclusiones recurriendo a los datos correspondientes, especialmente en este caso donde hemos comprobado que no están bien representadas:
prop.table(table(datos$rama, datos$fINEM), 1)##
## fINEM_no fINEM_si
## Artes-Humanid. 0.2595745 0.7404255
## Ciencias 0.1875000 0.8125000
## Ingen.-Arq. 0.2435897 0.7564103
## Salud 0.3170732 0.6829268
## Social-Jurid. 0.2979890 0.7020110prop.table(table(datos$rama, datos$fAnuncios), 1)##
## fAnuncios_no fAnuncios_si
## Artes-Humanid. 0.14468085 0.85531915
## Ciencias 0.11250000 0.88750000
## Ingen.-Arq. 0.07264957 0.92735043
## Salud 0.12195122 0.87804878
## Social-Jurid. 0.15722121 0.84277879En relación a la tendencia a opositar o no entre los titulados por ramas se observa lo siguiente. En el gráfico con el plano 1-2, por la cercanía entre Ingeniería-Arquitectura y fOposic_no, se deduce que tiene que haber mayor porcentaje de titulados de esta rama que no oposite frente a los que sí. Lo mismo ocurre con los titulados de la rama de Salud. En el caso de Artes-Humanidades y Social-Jurídico se deduce, de sus posiciones aproximadamente equidistantes de fOposic_si y fOposic_no, parecidos porcentajes de individuos que opositan o no en cada rama. Idénticas conclusiones se obtienen observando el plano 2-3, como era de esperar. La siguiente tabla con las distribuciones de frecuencias de la variable fOposic condicionadas a cada una de las ramas permite corroborar estas conclusiones:
prop.table(table(datos$rama, datos$fOposic), 1)##
## fOposic_no fOposic_si
## Artes-Humanid. 0.5148936 0.4851064
## Ciencias 0.6625000 0.3375000
## Ingen.-Arq. 0.8547009 0.1452991
## Salud 0.7560976 0.2439024
## Social-Jurid. 0.5118830 0.48811702. Variable suplementaria: número de formas usadas al buscar trabajo
Como ya se ha visto, las 8 categorías correspondientes a las variables de búsqueda de empleo mediante anuncios, INEM, ETT y contactos están aceptablemente representadas en la dimensión 1 con gran diferencia respecto de las demás. Además, coinciden con las que más contribuyen a esa dimensión. Ello hace que las conclusiones acerca de las categorías que se obtengan a través de la dimensión 1, puedan centrarse en esas 8 Un examen de su posición en relación al eje de la dimensión 1 muestra que, un desplazamiento en ese eje desde su extremo derecho hacia su extremo izquierdo, supone moverse entre individuos que reconocen un uso simultáneo de una cantidad cada vez mayor de esas cuatro formas de búsqueda de empleo. A la derecha del eje se encuentran los individuos que afirman no usar ninguna de ellas. Inmediatamente a su izquierda, los que afirman usar una de ellas. Más a la izquierda dos, y así sucesivamente, hasta llegar al extremo izquierdo del eje, donde se sitúan los que afirman usar las cuatro.
Para terminar de corroborar esa interpretación, se puede crear una variable nueva que mida cuántas de esas formas de búsqueda de empleo usa el entrevistado, incluir esa categoría como suplementaria en el ACM y representar la nube de puntos de los individuos coloreados según el valor que tenga cada uno para esa variable. Si se añaden las convenientes elipses de concentración, se facilita extraordinariamente la visualización del gráfico resultante.
datos$nueva <- (datos$fAnuncios == "fAnuncios_si") + (datos$fINEM=="fINEM_si") +
(datos$fETTs == "fETTs_si") + (datos$fContactos == "fContactos_si")
datos$nueva <- as.factor(datos$nueva)
levels(datos$nueva) <- c("Ninguna", "Usa 1", "Usa 2", "Usa 3", "Usa 4")
res.mca <- FactoMineR::MCA(datos[, 5:12], quali.sup = 8, graph = FALSE)
factoextra::fviz_mca_biplot(res.mca, axes = c(1, 2),
geom.ind = "point", geom.var = c("point", "text"),
col.ind = datos$nueva,
select.var = list(name = levels(datos$nueva)),
addEllipses = TRUE,
palette = c("black", "green", "blue", "orange", "grey"),
invisible = "var",
arrows = c(F, T),
title = "Concentración de individuos según el nº de formas de buscar empleo usadas")
La interpretación anterior se puede afinar y profundizar si dejamos a un lado la búsqueda de empleo basada en contactos y sus dos categorías asociadas. Su eliminación está justificada por varias razones:
la relación de la variable con la dimensión 1 es notablemente menor que la de las otras tres.
el cos2 de sus categorías es bastante menor que el de las categorías de las otras tres variables.
en el eje de la dimensión 1, la posición de sus categorías no está claramente diferenciada de algunas de las categorías de las otras tres variables.
Nótese que, en el caso de esta variable suplementaria, la calidad de la representación en el plano 1-2 de sus categorías es superior a la obtenida para las categorías de la rama de conocimiento:
rowSums(res.mca$quali.sup$cos2[,1:2]) # cos2 en el plano 1-2## Ninguna Usa 1 Usa 2 Usa 3 Usa 4
## 0.31014189 0.28222248 0.07775323 0.06689498 0.44848088Moverse en la dimensión 1 de derecha a izquierda supone considerar individuos que cada vez declaran usar una más de las tres formas de busqueda que aún se consideran (anuncios, INEM y ETTs). Pero el declarar una forma de búsqueda usada más, tiene unas características especiales. En el gráfico Nube proyectada de las categorías en el plano 1-2 según cos2 se observa que a la derecha están los individuos que declaran no usar ninguna. A la izquierda de estos, los que declaran usar una pero que en su mayoría indican que la que usan es simplemente mirar anuncios. Más a la izquierda, los que declaran otra más, además de esa, y que es apuntarse al INEM. Y más a la izquierda, los que declaran, además, tamién usar las ETT. Parece que la tendencia general en relación a estas tres formas de buscar empleo es: no usarlas, usar solo anuncios, usar anuncios e INEM o, finalmente, usar las tres. Las otras combinaciones (por ejemplo, solo ETTs, o solo INEM y ETTs o …) deben ser muy minoritarias.
Para confirmar esta interpretación, se puede repetir el análisis anterior pero definiendo una nueva variable suplementaria que clasifique a los entrevistados según los cuatro posibles comportamientos descritos más un quinto que recogería cualquier otra posibilidad.
datos$nueva <- "Otras"
datos$nueva[datos$fAnuncios=="fAnuncios_no" & datos$fINEM=="fINEM_no" & datos$fETTs=="fETTs_no"] <- " Ninguna"
datos$nueva[datos$fAnuncios=="fAnuncios_si" & datos$fINEM=="fINEM_no" & datos$fETTs=="fETTs_no"] <- "Anun"
datos$nueva[datos$fAnuncios=="fAnuncios_si" & datos$fINEM=="fINEM_si" & datos$fETTs=="fETTs_no"] <- "Anun+Inem"
datos$nueva[datos$fAnuncios=="fAnuncios_si" & datos$fINEM=="fINEM_si" & datos$fETTs=="fETTs_si"] <- "Anun+INEM+ETTs"
datos$nueva = as.factor(datos$nueva)Se observa que la categoría Otras solo es declarada por algo menos del 12% de los entrevistados:
100*table(datos$nueva)/length(datos$nueva)##
## Ninguna Anun Anun+Inem Anun+INEM+ETTs Otras
## 6.573541 14.626130 31.717338 35.332786 11.750205Los siguientes gráficos apoyan la interpretación anterior.
res.mca <- FactoMineR::MCA(datos[, 1:12], quali.sup = c(1:4,12), graph = FALSE)
factoextra::fviz_mca_biplot(res.mca, axes = c(1, 2),
geom.ind = "point", geom.var = c("point", "text"),
col.ind = datos$nueva,
select.var = list(name = levels(datos$nueva)),
addEllipses = TRUE,
palette = c("black", "green", "blue", "orange", "grey"),
arrows = c(F, T),
title = "Concentración de individuos según la variable suplementaria nueva")
Aplicación shiny
En el paquete Factoshiny se encuentran algunas aplicaciones shiny que permiten ejecutar las funciones del paquete FactoMineR de forma interactiva en un formato web con menús. Para realizar un análisis de correspondencias múltiple, una vez instalado y cargado el paquete, se utiliza la función MCAshiny:
install.packages("Factoshiny")
library(Factoshiny)
MCAshiny(res.mca)
El código anterior tiene como resultado que se abra la siguiente página en su navegador desde la que puede interactuar:

ACM con el paquete ca
En el caso del paquete ca la función que lleva a cabo el ACM es mjca(datos, nd, lambda, ...). El argumento nd permite especificar el número de dimensiones que debe mostrar, por defecto muestra 2. El argumento lambda presenta varias opciones, en particular, “indicator” es la que se debe utilizar si se desea realizar el análisis sobre la tabla disyuntiva completa (igual que el paquete FactoMineR). Sin embargo, la opción por defecto es “adjusted” que realiza un ajuste que permite aumentar el porcentaje de inercia de las categorías recogido en las primeras dimensiones (contribución relativa), consiguiendo así que estén mejor representadas. Realizamos, en primer lugar, el análisis con la opción “indicator”:
res.mca2 <- ca::mjca(datos[, 5:11], nd = 3, lambda = "indicator")
summary(res.mca2)##
## Principal inertias (eigenvalues):
##
## dim value % cum% scree plot
## 1 0.231434 23.1 23.1 ******
## 2 0.159246 15.9 39.1 ****
## 3 0.148893 14.9 54.0 ****
## 4 0.140175 14.0 68.0 ****
## 5 0.117339 11.7 79.7 ***
## 6 0.105556 10.6 90.3 ***
## 7 0.097357 9.7 100.0 **
## -------- -----
## Total: 1.000000 100.0
##
##
## Columns:
## name mass qlt inr k=1 cor ctr k=2 cor
## 1 | fAnuncios:fAnuncios_no | 19 466 133 | 1740 458 246 | -222 7
## 2 | fAnuncios:fAnuncios_si | 124 466 20 | -263 458 37 | 34 7
## 3 | fINEM:fINEM_no | 38 497 110 | 1059 407 184 | 345 43
## 4 | fINEM:fINEM_si | 105 497 40 | -384 407 67 | -125 43
## 5 | fETTs:fETTs_no | 83 527 64 | 565 441 114 | 105 15
## 6 | fETTs:fETTs_si | 60 527 88 | -780 441 158 | -146 15
## 7 | fContactos:fContactos_no | 58 463 85 | 653 292 107 | -208 30
## 8 | fContactos:fContactos_si | 85 463 58 | -446 292 73 | 142 30
## 9 | fOposic:fOposic_no | 87 669 53 | -62 6 1 | 654 658
## 10 | fOposic:fOposic_si | 56 669 82 | 95 6 2 | -1007 658
## 11 | fAutonomo:fAutonomo_no | 132 630 10 | 37 17 1 | -18 4
## 12 | fAutonomo:fAutonomo_si | 11 630 123 | -454 17 10 | 220 4
## 13 | fOtra:fOtra_no | 119 526 22 | -5 0 0 | -266 357
## 14 | fOtra:fOtra_si | 24 526 112 | 27 0 0 | 1343 357
## ctr k=3 cor ctr
## 1 6 | -1 0 0 |
## 2 1 | 0 0 0 |
## 3 28 | -359 47 33 |
## 4 10 | 130 47 12 |
## 5 6 | -226 71 29 |
## 6 8 | 313 71 39 |
## 7 16 | 455 142 81 |
## 8 11 | -311 142 55 |
## 9 232 | -53 4 2 |
## 10 358 | 82 4 3 |
## 11 0 | 223 610 44 |
## 12 3 | -2730 610 541 |
## 13 53 | -183 169 27 |
## 14 267 | 924 169 135 |Esta salida devuelve, también, la inercia de las 7 dimensiones posibles ordenadas de mayor a menor junto con el porcentaje que representa sobre la inercia total y porcentaje acumulado. Seguidamente se obtiene una tabla para las categorías (columnas) con la siguiente información:
mass: frecuencia relativa de la categoría expresada en tanto por 1000.qlt: calidad total, esto es, la suma de las contribuciones relativas dadas encor.inr: parte de la inercia total (en tanto por mil) del punto en el espacio de filas y columnas.k=1,k=2yk=3: puntuaciones o coordenadas obtenidas para las categorías en la dimensión i (k=i)cor: proporción (en tanto por mil) de la inercia de la variable que es recogida por la dimensión, esto es, la contribución relativa. Coincide con el cuadrado de la correlación de la categoría con la dimensión correspondiente.ctr: contribución de la categoría a la dimensión o contribución absoluta, esto es, el tanto por mil de la inercia de la dimensión que es explicado por cada categoría.
Se puede observar que los resultados coinciden con los obtenidos con el paquete FactoMineR. Sin embargo, para obtener el gráfico de las categorías en el plano (dim 1, dim 2) debemos ejecutar el siguiente código (si se desea otro plano, por ejemplo el plano (dim 1, dim 3) se debería incluir el argumento dim = c(1, 3)):
plot(res.mca2)
Si utilizamos la opción “adjusted” los resultados varían, en particular, cambian las coordenadas y las contribuciones relativas:
res.mca.ajust <- ca::mjca(datos[, 5:11], nd = 3, lambda = "adjusted")
summary(res.mca.ajust)##
## Principal inertias (eigenvalues):
##
## dim value % cum% scree plot
## 1 0.010679 74.6 74.6 ************************
## 2 0.000366 2.6 77.1 *
## 3 5e-05000 0.3 77.5
## -------- -----
## Total: 0.014316
##
##
## Columns:
## name mass qlt inr k=1 cor ctr k=2 cor
## 1 | fAnuncios:fAnuncios_no | 19 785 133 | 374 785 246 | 11 1
## 2 | fAnuncios:fAnuncios_si | 124 785 20 | -57 785 37 | -2 1
## 3 | fINEM:fINEM_no | 38 821 110 | 227 816 184 | -17 4
## 4 | fINEM:fINEM_si | 105 821 40 | -83 816 67 | 6 4
## 5 | fETTs:fETTs_no | 83 787 64 | 121 785 114 | -5 1
## 6 | fETTs:fETTs_si | 60 787 88 | -168 785 158 | 7 1
## 7 | fContactos:fContactos_no | 58 883 85 | 140 875 107 | 10 4
## 8 | fContactos:fContactos_si | 85 883 58 | -96 875 73 | -7 4
## 9 | fOposic:fOposic_no | 87 381 53 | -13 58 1 | -31 322
## 10 | fOposic:fOposic_si | 56 381 82 | 20 58 2 | 48 322
## 11 | fAutonomo:fAutonomo_no | 132 585 10 | 8 460 1 | 1 5
## 12 | fAutonomo:fAutonomo_si | 11 585 123 | -98 460 10 | -11 5
## 13 | fOtra:fOtra_no | 119 338 22 | -1 3 0 | 13 314
## 14 | fOtra:fOtra_si | 24 338 112 | 6 3 0 | -64 314
## ctr k=3 cor ctr
## 1 6 | 0 0 0 |
## 2 1 | 0 0 0 |
## 3 28 | -7 1 33 |
## 4 10 | 2 1 12 |
## 5 6 | -4 1 29 |
## 6 8 | 6 1 39 |
## 7 16 | 8 3 81 |
## 8 11 | -6 3 55 |
## 9 232 | -1 0 2 |
## 10 358 | 1 0 3 |
## 11 0 | 4 120 44 |
## 12 3 | -50 120 541 |
## 13 53 | -3 22 27 |
## 14 267 | 17 22 135 |plot(res.mca.ajust)
Con la opción “adjusted” se han conseguido unas dimensiones que recogen más inercia de las categorías que antes. La importancia de cada categoría dentro de la dimensión (contribución absoluta) es la misma pero ahora están mejor representadas.

Grupo Innovación Docente: Estadística en Ciencias Sociales. Universidad de Murcia.
Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-CompartirIgual 4.0 Internacional.