|
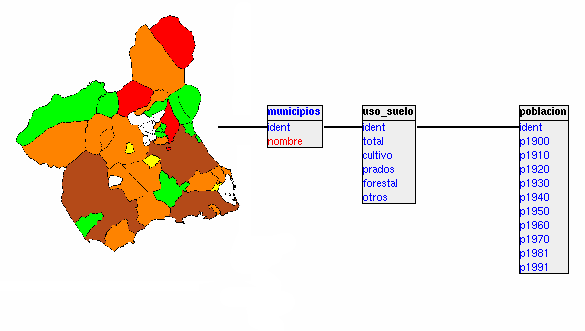
Es el modelo más utilizado hoy en día. Una base de datos relacional es básicamente un conjunto de tablas, similares a las tablas de una hoja de cálculo, formadas por filas (registros) y columnas (campos). Los registros representan cada uno de los objetos descritos en la tabla y los campos los atributos (variables de cualquier tipo) de los objetos. En el modelo relacional de base de datos, las tablas comparten algún campo entre ellas. Estos campos compartidos van a servir para establecer relaciones entre las tablas que permitan consultas complejas (figura 90). En esta figura aparecen tres tablas con información municipal, en la primera aparecen los nombres de los municipios, en la segunda el porcentaje en cada municipio de los diferentes usos del suelo y en la tercera la población en cada municipio lo largo del siglo XX. Como campo común aparece ident, se trata de un identificador numérico, único para cada municipio37
La idea básica de las bases de datos relacionales es la existencia de entidades (filas en una tabla) caracterizadas por atributos (columnas en la tabla). Cada tabla almacena entidades del mismo tipo y entre entidades de distinto tipo se establecen relaciones38. Las tablas comparten algún campo entre ellas, estos campos compartidos van a servir para establecer relaciones entre las tablas. Los atributos pueden ser de unos pocos tipos simples:
Estos tipos simples se denominan tipos atómicos y permiten una mayor eficacia en el manejo de la base de datos pero a costa de reducir la flexibilidad a la hora de manejar los elementos complejos del mundo real y dificultar la gestión de datos espaciales, en general suponen un problema para cualquier tipo de datos geométricos.
Las relaciones que se establecen entre los diferentes elementos de dos tablas en una base de datos relacional pueden ser de tres tipos distintos:
El lenguaje de consultas SQL (Lenguaje Estructurado de Consultas) se ha convertido, debido a su eficiencia, en un estandar para las bases de datos relacionales. A pesar de su estandarización se han desarrollado, sobre una base común, diversas versiones ampliadas como las de Oracle o la de Microsoft SQL server.
Es un lenguaje declarativo en el que las órdenes especifican cual debe ser el resultado y no la manera de conseguirlo (como ocurre en los lenguajes procedimentales). Al ser declarativo es muy sistemático, sencillo y con una curva de aprendizaje muy agradable. Sin embargo los lenguajes declarativos carecen de la potencia de los procedimentales. El gran éxito de las bases de datos relacionales se debe en parte a la posibilidad de usar este lenguaje. Incluye diversos tipos de capacidades:
En una base de datos relacional, los resultados de la consulta van a ser datos individuales, tuplas39 o tablas generados a partir de consultas en las que se establecen una serie de condiciones basadas en valores numéricos. Por ejemplo una típica consulta sobre una tabla en una base de datos relacional, utilizando SQL podría ser:
SELECT id, nombre, pob1991 FROM municipios WHERE pob1991>20000;
el resultado será una tabla en la que tendremos tres columnas (id, nombre, poblacion) procedentes de la tabla municipios, las filas corresponderán sólo a aquellos casos en los que la poblacion en 1991 (columna pob1991) sea mayor que 20000. En el caso de que sólo uno de los municipios cumpliera la condición obtendríamos una sola fila (una tupla) y en caso de que la consulta fuera:
SELECT pob1991 FROM municipios WHERE pob1991>20000;
obtendríamos un sólo número, la población del municipio más poblado.
Lo más habitual es utilizar el SGBD para almacenar la información temática y el SIG para la información geométrica y topológica. Una de las funcionalidades de este modelo será el enlazado de ambos tipos de información que se almacenana de formas completamente diferentes. Se trata del modelo de datos geo-relacional.
El mayor interés del modelo geo-relacional estará en poder lanzar una consulta SQL y obtener una o varias entidades espacial (en lugar de número, tabla o fila) como respuesta. Para ello debe enlazarse la base de datos espacial (mapa vectorial) con la base de datos temática (tablas) mediante una columna en una de las tablas de la base de datos que contenga los mismos identificadores que las entidades en la base de datos espacial.
Podemos pensar en un mapa vectorial como en una tabla en la que cada registro (fila) es un objeto (polígono, linea o punto) que contiene un campo identificador y un campo que contiene la localización (conjunto de coordenadas X e Y de tamaño, lógicamente, variable). El hecho de que esta información se presente en forma de tabla o en forma de mapa es simplemente una cuestión de conveniencia.
Si pedimos, como resultados de una consulta a la base de datos temática, estos identificadores comunes, en realidad lo que estamos obteniendo son objetos espaciales (polígonos en el caso de los municipios). Los resultados de las consultas podrían presentarse de esta manera en forma de mapa en lugar de en forma de tabla de modo que a los diferentes polígonos se le asignarían diferentes colores en función de que se cumpliera o no una condición, o de los valores que adoptase una variable o índice. Por ejemplo la consulta
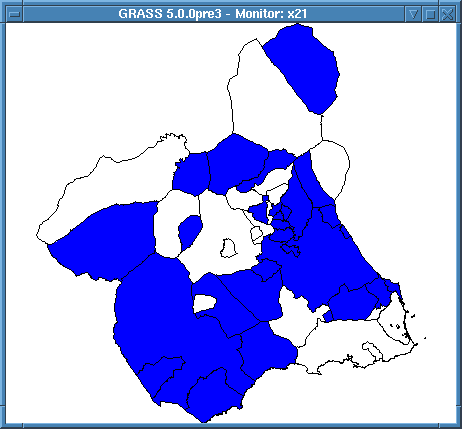
SELECT ident, nombre FROM municipios WHERE 1000*(pob1991-pob1981)/pob1981>0 AND pob1981>0;
para obtener aquellos municipios con una tasa de crecimiento de población positiva entre 1981 y 1991 en tantos por mil, podría representarse en un SIG tal como aparece en la figura 92.
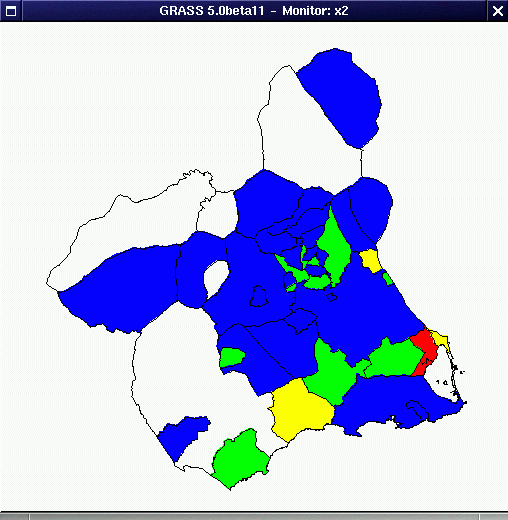
Una consulta similar a la anterior pero estableciendo una reclasificación por colores daría el resultado que puede verse en la figura 93 en la que el que el color rojo indica valores mayores de 50, el amarillo entre 30 y 50, el verde entre 20 y 30, el azul entre 10 y 20 y el blanco menor de 10.
En estos casos se necesita un módulo específico que transforme los resultados de las consultas en una serie de reglas para pintar los polígonos asignando al mismo tiempo una paleta de colores definida por el usuario.
En definitiva la única diferencia entre el trabajo de un gestor tradicional de bases de datos y el enlace de un SIG a base de datos es el modo de presentación (tabla o mapa). Casi todo el trabajo lo hace el gestor de bases de datos y el Sistema de Información Geográfica, se limita a presentar los resultados.
Hasta ahora lo que hemos hecho es obtener objetos espaciales como resultado de una consulta, pero cuando se trabaja con un SIG enlazado a una base de datos, se pretende que las consultas incluyan tambien condiciones espaciales. Incluso deberíamos ser capaces de llevar a cabo consultas interactivas en las que las condiciones se formulan en función de donde haya pinchado el usuario en un mapa mostrado en pantalla.
Sin embargo en el modelo geo-relacional toda la información geométrica y topológica está en el SIG no en el SGBD por tanto las consultas deberán preprocesarse y postprocesarse.
Preprocesamiento significa que el módulo encargado de construir de forma automática consultas SQL como las que hemos visto antes, y lanzarlas al programa servidor de bases de datos, deberá hacerlo teniendo en cuenta una serie de criterios espaciales definidos por el usuario. Por ejemplo, si el usuario pincha en la pantalla dentro de un polígono esperando obtener nombre y población del municipio, el módulo deberá determinar de que polígono se trata e incluir su identificador, por ejemplo 17, como condición que debe cumplirse:
SELECT nombre, pob1991 FROM municipios WHERE id==17;
Postprocesamiento implica que los resultados de la consulta SQL deberán filtrarse para determinar cuales cumplen determinadas condiciones relacionada con el espacio. Para ello, una de las columnas pedidas en la consulta ha de ser el identificador a partir del cual se obtiene, ya en el SIG, la geometría del polígono a la que se puede aplicar la operación de análisis espacial (distancia, cruce, inclusión, adyacencia, etc.) necesaria para derminar si se cumple o no la condición. Aquellos casos en los que si se cumple constituye la salida del módulo, el resto se deshechan.