Resumen teórico
Introducción
El análisis de conglomerados es una técnica multivariante utilizada para clasificar una muestra de elementos o individuos en grupos, de forma que las observaciones pertenecientes a un grupo sean similares entre sí (homogeneidad dentro los grupos) y diferentes del resto (heterogeneidad entre ellos) sobre la base de un conjunto definido de variables. En concreto, realiza una partición de los individuos en un conjunto de grupos de modo que un individuo pertenece solo a un grupo y la unión de dichos grupos contiene a todos los individuos. Estos grupos se denominan conglomerados.
Esta técnica puede emplearse, por ejemplo, para agrupar países, comunidades autónomas, regiones o provincias con características similares, en relación con el empleo, o con la composición de la población, etc. También puede usarse para formar grupos de consumidores teniendo en cuenta sus preferencias en nuevos productos, niveles de gasto, etc.
El análisis de conglomerados es un método basado en criterios geométricos y se utiliza fundamentalmente como una técnica exploratoria, descriptiva pero no explicativa.
Planteamiento del problema
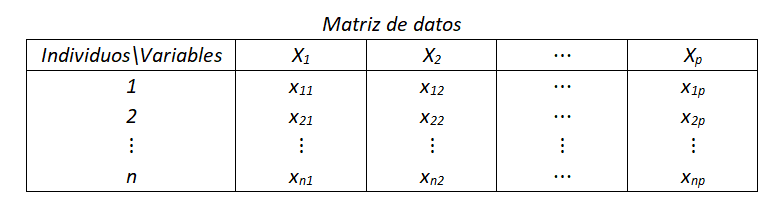
A partir de un conjunto de n individuos sobre los que se observan p variables, \(X_1,…,X_p\), se tiene una matriz \((x_{ij})\) formada por las observaciones de las p variables para cada uno de los individuos, siendo \(x_{ij}\) el valor de la variable \(X_j\) en el individuo i-ésimo \(i = 1,…,n; j = 1,…,p\).
Para llevar a cabo el análisis es necesario:
Elegir una medida de distancia o disimilaridad que informe sobre las diferencias entre los valores de los individuos sobre un conjunto de variables. En general, se suele usar la matriz de distancias euclídea cuando se trabaja con variables cuantitativas. Si las variables son cualitativas se suele emplear la distancia chi-cuadrado.
Determinar una regla o criterio para agrupar los individuos y asignarlos a los dintintos conglomerados.
Medidas de distancia
La distancia o disimilaridad entre dos individuos i y j, denotada por d(i,j), se define como aquella medida que calcula el grado de desemejanza entre ellos en relación a unas variables. Cuanto mayor sea d(i,j) mayor será la diferencia entre ambos elementos. La medida de distancia más utilizada para datos cuantitativos es la distancia euclídea al cuadrado que calcula las diferencias de los valores observados en cada una de las variables en cada par de individuos distintos:
\[ d(i,j)^2={\sum_{h=1}^p\left(x_{ih}-x_{jh}\right)^2} \]
Un problema de la distancia euclídea, como medida de disimilaridad, es su dependencia de las diferentes escalas en que estén medidas las variables. Para solucionarlo se suelen tipificar los datos de las variables y a partir de ellos se calcula la distancia euclídea.
Además, si hay una correlación alta entre algunas variables, es conveniente resumir la información de esas variables en otro grupo menor de variables, realizando, por ejemplo, un análisis de componentes principales.
Método de agrupación
Una vez que se ha obtenido la matriz de disimilaridades, el paso siguiente es aplicar una regla que nos permita agrupar a los individuos similares, es decir, establecer un método de clasificación.
Los métodos que se pueden emplear para agrupar se suelen clasificar en jerárquicos y no jerárquicos. Se diferencian en que los métodos jerárquicos obtienen las agrupaciones basándose en una estructura encadenada de grupos (desde un solo grupo formado por todos los individuos a n grupos formados cada uno por un solo individuo, o a la inversa, de n grupos a uno solo) y los no jerárquicos dividen el conjunto de individuos en k grupos, siendo k un parámetro definido previamente.
1. Métodos jerárquicos
Se trata de obtener diferentes agrupaciones, organizadas en diferentes niveles jerárquicos, estando cada partición formada por clases disjuntas. Se distingue entre:
Método asociativo o aglomerativo: los individuos van uniéndose en pasos sucesivos al conglomerado al que son más próximos.
Método disociativo o divisivo: parte de un solo conglomerado que contiene todos los individuos y a través de sucesivas divisiones se forman grupos cada vez mas pequeños.
Los métodos más usados para la agrupación jerárquica aglomerativa son:
Método de la distancia mínima (también conocido como el vecino más próximo) que asigna como distancia entre conglomerados el valor mínimo de las distancias entre todos los individuos que componen los conglomerados comparados.
Método de la distancia máxima (vecino más lejano) que toma como distancia entre conglomerados el valor máximo de las distancias entre todos los individuos de los comglomerados que se están comparando.
Método de la distancia media (vinculación entre grupos) que asigna como distancia entre conglomerados el valor medio de las distancias entre todos los individuos que componen los conglomerados.
Método de Ward, que realiza la agrupación teniendo en cuenta que el incremento en la suma de las variabilidades de los grupos sea lo menor posible. En general, se considera que la clasificación obtenida por este método es mejor que la ofrecida por otros métodos.
Los resultados se recogen en un gráfico denominado dendograma, en el que la distancia de agrupamiento aparece en un eje y los individuos en otro.
Si por ejemplo, \(n = 10\), un dendograma posible sería
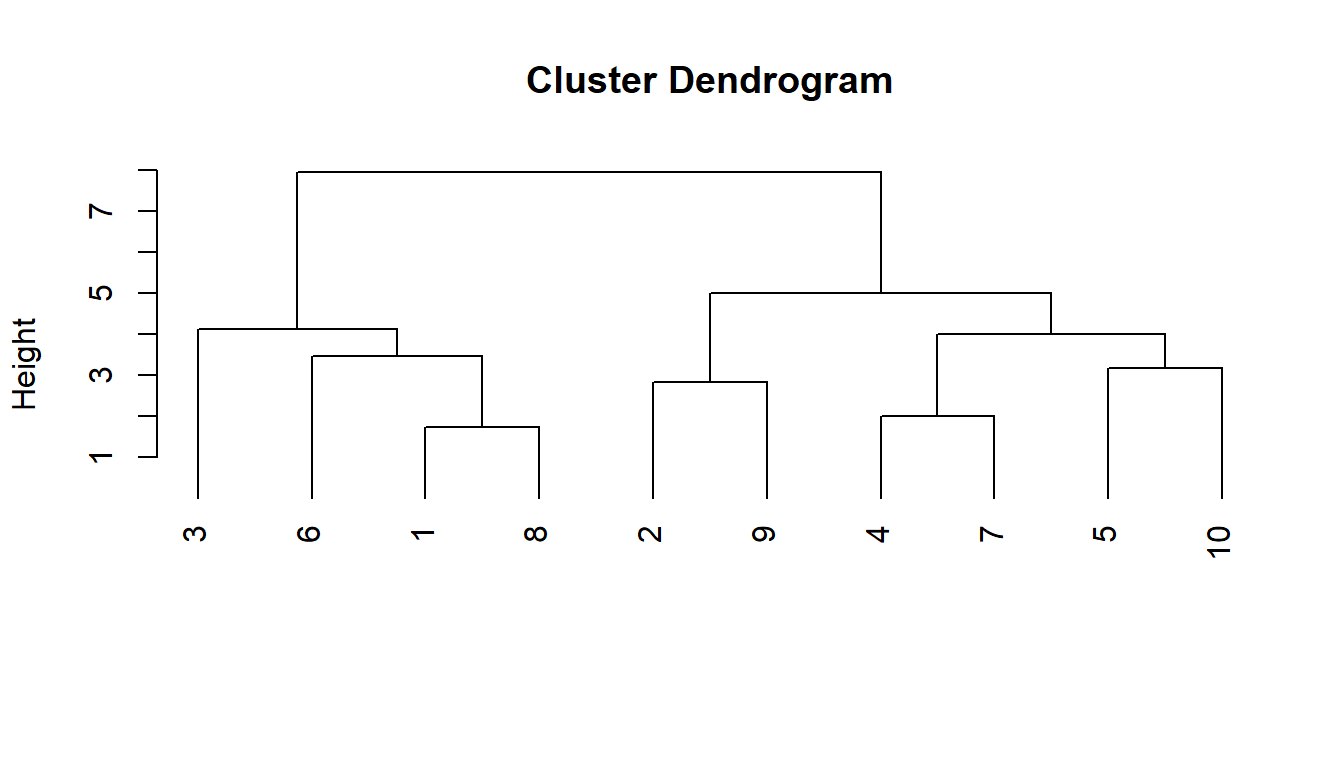
Los conglomerados están representados mediante trazos horizontales y las etapas de unión mediante trazos verticales. La separación entre las etapas de unión es proporcional a la distancia a la que están los grupos que se unen en esa etapa. Se observa cómo los individuos 1 y 8 son los más similares y por eso son los primeros que se unen formando un conglomerado, y éstos se agrupan posteriormente con el 6 y el 3. Algo similar ocurre con los individuos 4 y 7, que se unen al 5 y al 10 (que ya se habían unido previamente porque eran más similares entre sí que a los individuos 4 y 7) y después con el 2 y 9. Si se corta un dendograma a una altura concreta sobre el eje de la distancia, se obtienen los conglomerados. Así, en este gráfico, si se traza una línea a una altura del eje de ordenadas igual a 6, se corta la línea de unión de todos los elementos y aparecen los dos conglomerados.
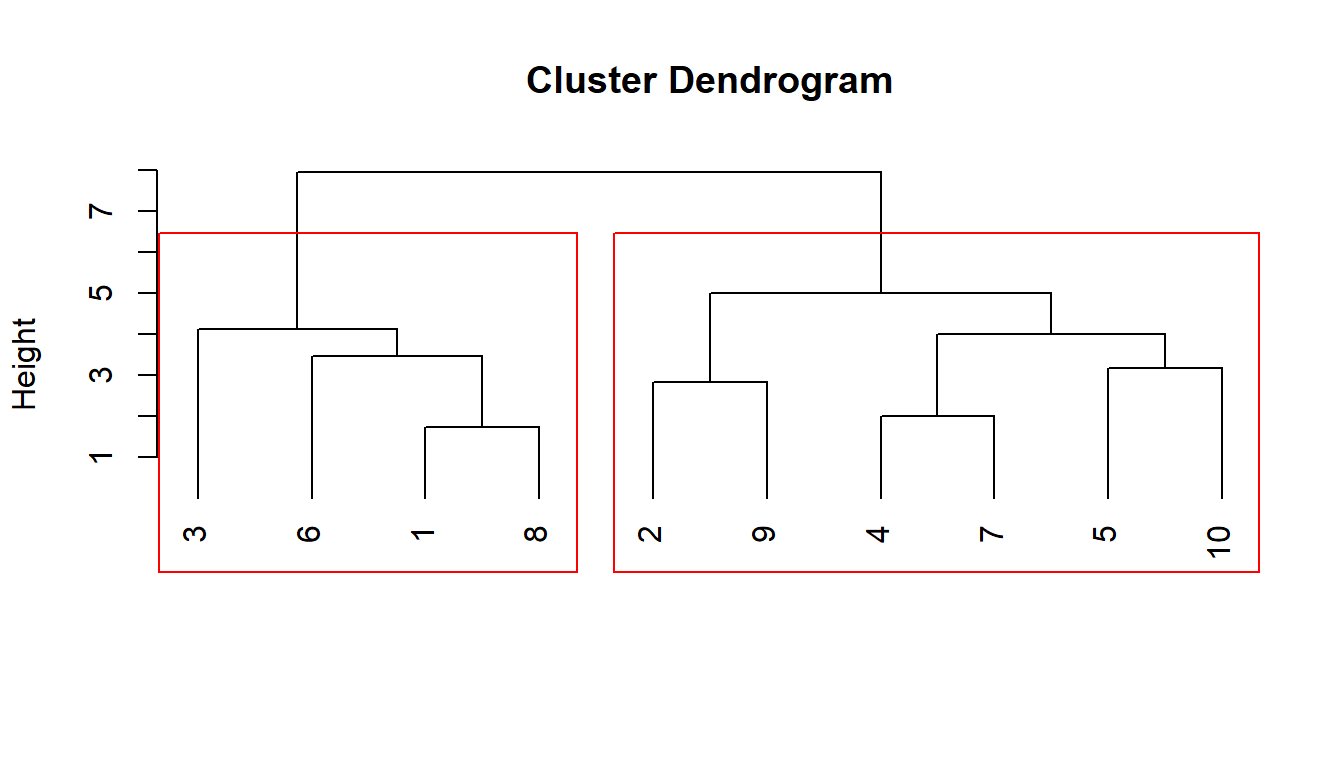
El problema reside en decidir por dónde hay que cortar, lo que determinará el número de conglomerados. Para ello nos podemos basar en la distancia que aparece en el dendograma (Height). En los primeros pasos los saltos en las distancias serán pequeños, siendo mayores en los últimos pasos. El punto de corte más adecuado será aquel en el que comiencen a producirse saltos bruscos (indicación de grupos distantes y por tanto diferentes). Otro procedimiento está basado en el gráfico de sedimentación que tiene en el eje de ordenadas la variabilidad entre grupos correspondiente a cada posible número de conglomerados y, en el eje de abcisas, el número de conglomerados. Esta gráfica tiene una fuerte pendiente negativa al principio que se va suavizando. Basta con fijarse en el punto en el cual la pendiente es muy pequeña y, por tanto, el decrecimiento muy lento (donde se forma un “codo”). El número de conglomerados óptimo es el valor donde se produce este cambio.
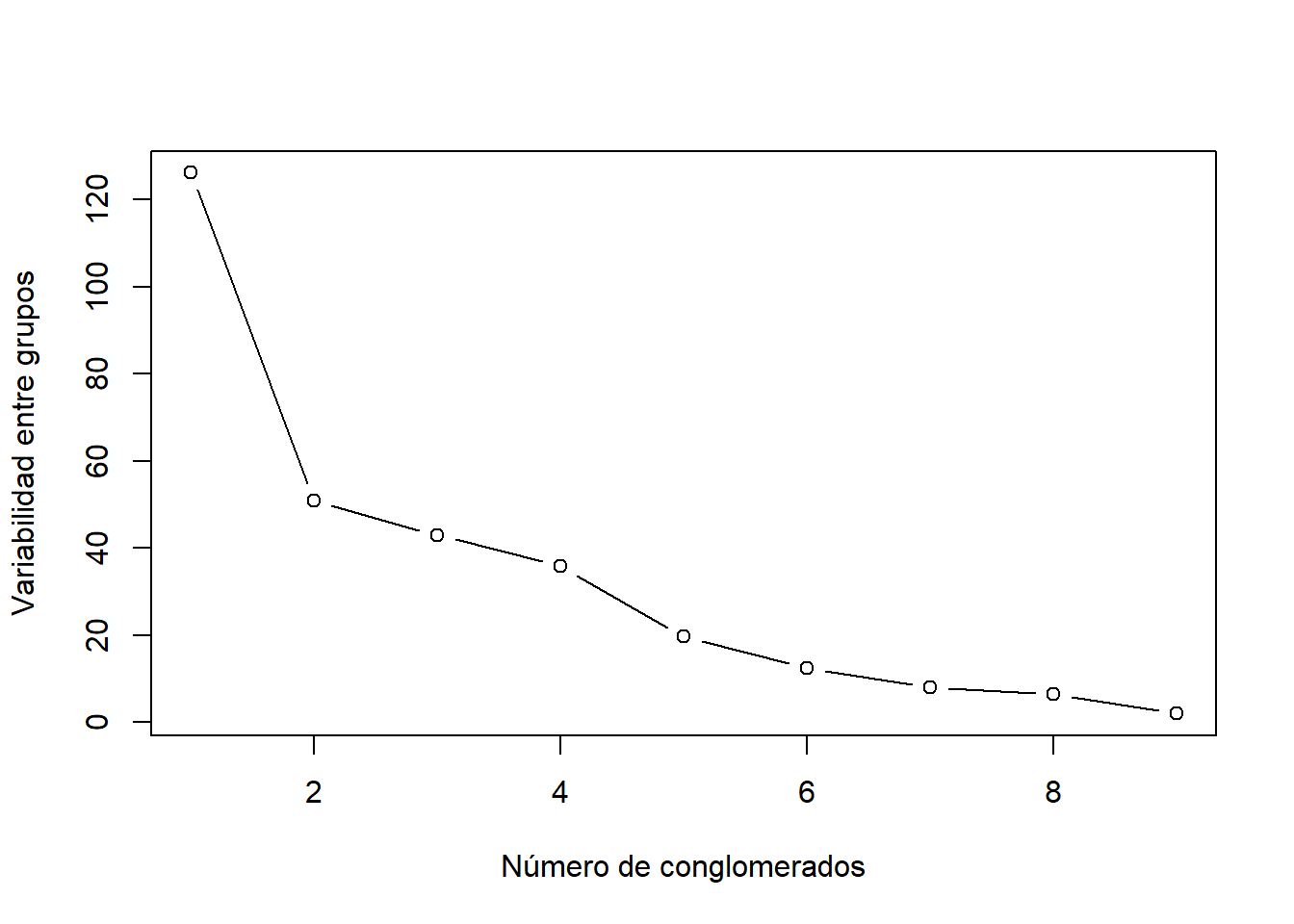
Con el criterio comentado anteriormente, podría considerarse válido seleccionar dos conglomerados, teniendo en cuenta el punto que forma el “codo” de la gráfica.
Adicionalmente, existe toda una serie de índices, disponibles en varios paquetes de R, que se pueden utilizar como ayuda para tomar esta decisión ya que no existe un criterio objetivo.
2. Métodos no jerárquicos
En estos métodos se forman \(k\) grupos siendo \(k\) un número determinado previamente. Para decidir el valor de \(k\) se utiliza el conocimiento que se tiene de investigaciones previas o el número de conglomerados que se ha determinado en la clasificación jerárquica. Hay que tener en cuenta que fijar un número muy pequeño puede llevar a conclusiones pobres, mientras que fijar un número demasiado grande puede complicar la interpretación.
De los distintos algoritmos de clasificación no jerárquicos el más utilizado es el método de \(k-medias\). Para llegar a la formación de conglomerados se sigue un proceso iterativo que comienza con una selección de tantos elementos como conglomerados se quieran formar. Estos elementos constituyen los centros iniciales de los grupos y permiten establecer una primera partición por asignación del resto de los elementos al centro más próximo.
Es, por tanto, necesario especificar a priori el número de conglomerados con el que se va a trabajar (arbitrario), así como los centros de los grupos, asignando cada individuo al grupo cuyo centro se encuentre más próximo. Una vez distribuidos todos los elementos se calculan los nuevos centros de los grupos denominados centroides, como la media de los elementos que lo forman. Se vuelve a agrupar a los individuos en torno a los centroides, dando lugar a una nueva partición. El proceso se detiene cuando coinciden dos soluciones consecutivas o bien las distancias entre los nuevos centroides no son muy diferentes de las de la etapa anterior, o cuando se alcanza el número máximo de iteraciones establecido previamente. Para elegir los centros iniciales, una opción bastante utilizada consiste en escoger los centroides de los grupos formados en el análisis jerárquico.
Este método es especialmente útil cuando se tiene un gran número de individuos para clasificar, pues realizar el de conglomerados jerárquico puede ser problemático ya que un dendograma con más de 50 individuos es difícil de representar e interpretar. El método de k-medias es el más robusto respecto a la presencia de outliers y errores en las medidas de distancia.
Interpretación del análisis de conglomerados
Esta técnica es descriptiva y puede ofrecer distintas soluciones dependiendo del método de análisis de conglomerados utilizado. Por ello, es importante validar y estudiar el perfil de los grupos, con el objetivo de confirmar la estabilidad de la solución.
Cuando trabajamos con métodos jerárquicos se puede emplear el coeficiente de correlación cofenético entre la matriz de distancias original y la denominada matriz cofenética para validar la estructura que proporciona el método jerárquico de que se trate. Con este coeficiente se mide la similitud entre las distancias iniciales (obtenidas a partir de los datos originales) y las distancias finales con las cuales los individuos se han unido durante el desarrollo del método jerárquico (matriz cofenética). Se calcula la correlación entre los \(n(n-1)/2\) elementos de la parte superior de la matriz de distancia observada y los correspondientes en la matriz cofenética. Valores de la correlación altos (cercanos o iguales a la unidad) indican que es válida la agrupación realizada.
En los métodos no jerárquicos, se suele utilizar el remuestreo, consistente en tomar varias muestras de los datos originales y realizar el análisis sobre cada una. Si las soluciones obtenidas en las diversas muestras no guardan una cierta similitud, se debe dudar de la estructura obtenida. También pueden emplearse técnicas estadísticas como el análisis multivariante de la varianza, o múltiples análisis de la varianza sobre cada variable en cada conglomerado, que permitirán verificar que el análisis de conglomerados que se ha realizado es adecuado. Pero al final, el conocimiento que el investigador tenga acerca del problema decidirá si los grupos obtenidos son significativos y, por tanto, es válido el análisis realizado.
Etapas de un análisis de conglomerados
Etapa 1: Exploración de los datos y selección de variables
La clasificación dependerá de las variables elegidas. Hay que seleccionar sólo aquellas variables que tengan que ver con los objetivos del análisis de conglomerados que se va a realizar.
Otra cuestión importante es observar las unidades de medida de la variables consideradas o su recorrido, ya que si difieren mucho, esto puede distorsionar el análisis de conglomerados al verse afectada la matriz de distancias. Para evitar que haya variables que pesen más que otras en el análisis, es conveniente tipificar los datos.
Etapa 2: Detección de valores atípicos
El análisis de conglomerados es muy sensible a la presencia de valores atípicos, por lo que es importante realizar una representación gráfica de los datos (por ejemplo, gráficos boxplot) y decidir si es necesario eliminar algún valor atípico.
Etapa 3: Estudio de la correlación
En caso de que existan altas correlaciones entre las variables, debe realizarse un análisis de componentes principales previo al análisis de conglomerados, ya que de no hacerlo las variables altamente correladas estarían implícitamente ponderadas con más fuerza.
Etapa 4. Selección de la medida de similitud y la técnica de agrupación
En esta etapa habría que decidir qué medida de similitud elegir y qué método de agrupación emplear para realizar el análisis y llevarlo a cabo.
Etapa 5: Interpretación de los conglomerados
Durante todo el proceso de determinación de los conglomerados se debe ir realizando una validación de los grupos en el sentido de que su composición sea razonable y coherente con las variables consideradas en el estudio. Determinados los grupos deben describirse en términos de las mismas, para lo que podemos apoyarnos en su representación gráfica por grupo utilizando gráficos boxplot.

Grupo Innovación Docente: Estadística en Ciencias Sociales. Universidad de Murcia.
Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial-CompartirIgual 4.0 Internacional.